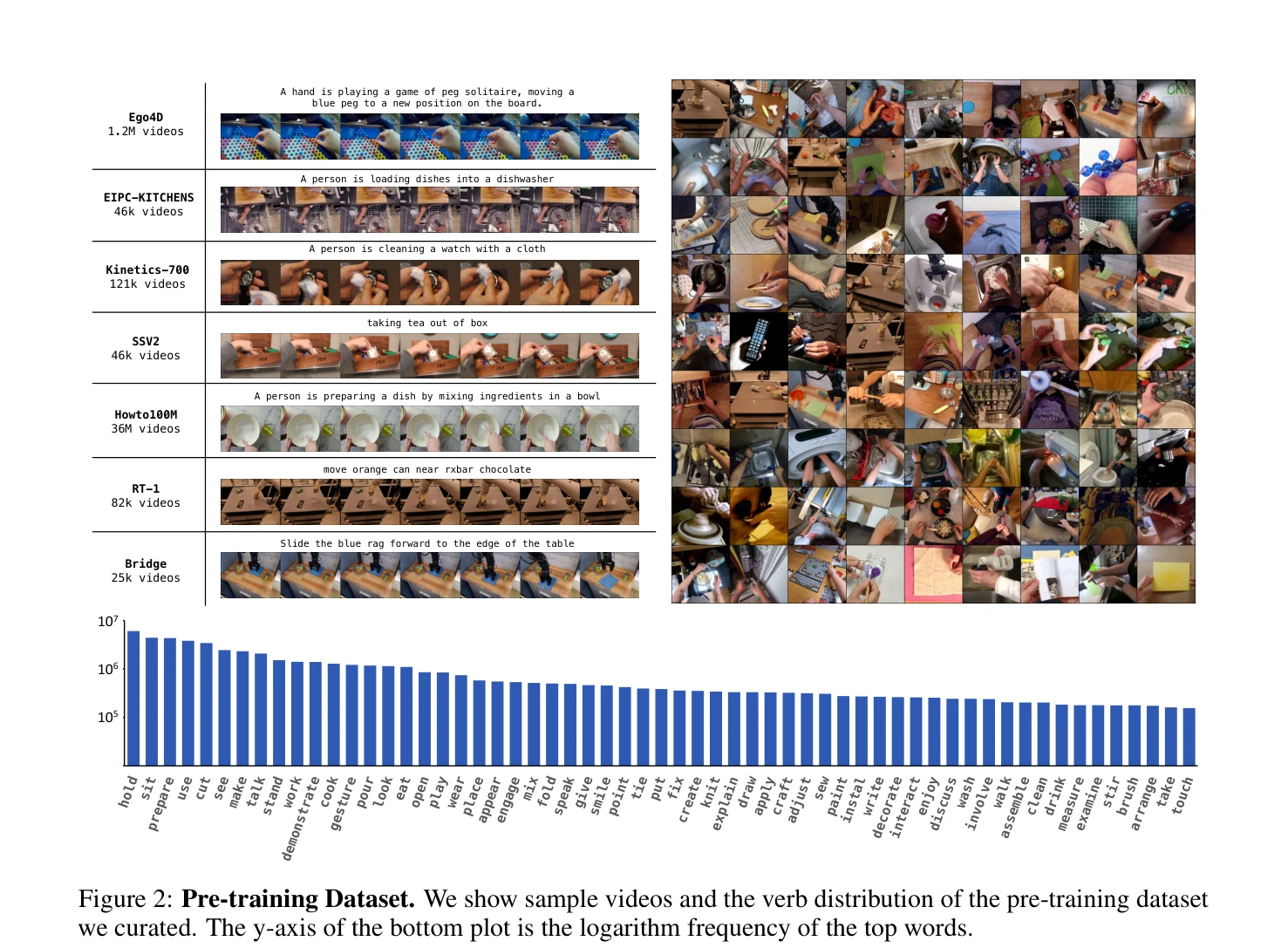
저자: Chi-Lam Cheang, Guangzeng Chen, Ya Jing, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Hongtao Wu, Jiafeng Xu, Yichu Yang, Hanbo Zhang, Minzhao Zhu | 날짜: 2024-10-08 | URL: https://arxiv.org/abs/2410.06158 📄 PDF
Essence
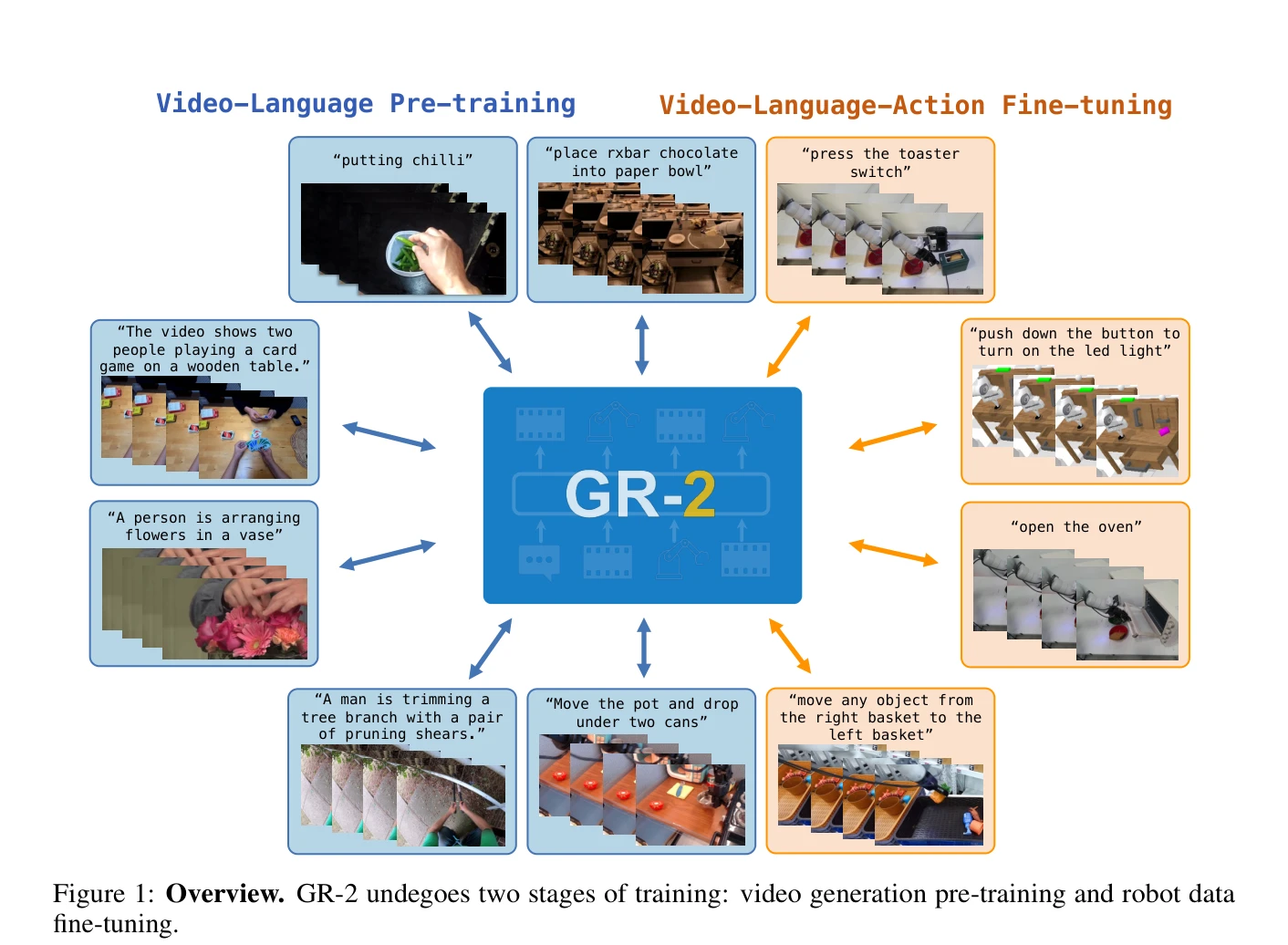
Figure 1: Overview. GR-2 undegoes two stages of training: video generation pre-training and robot data
GR-2는 38백만 개의 비디오 클립으로 대규모 사전학습한 후 로봇 궤적으로 미세조정하는 generative video-language-action 모델로, 100개 이상의 조작 작업에서 97.7% 평균 성공률을 달성하고 미보기 시나리오에 뛰어난 일반화를 보인다.
Evaluation
Novelty: 4/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: GR-2는 대규모 비디오 사전학습과 로봇 데이터 미세조정을 효과적으로 결합하여 로봇 조작의 일반화 능력을 획기적으로 향상시킨 논문이다. 100개 이상의 작업을 소수의 궤적으로 학습하고 미보기 시나리오에 강력한 성능을 보여 실제 로봇 응용에 높은 잠재력을 입증한다.