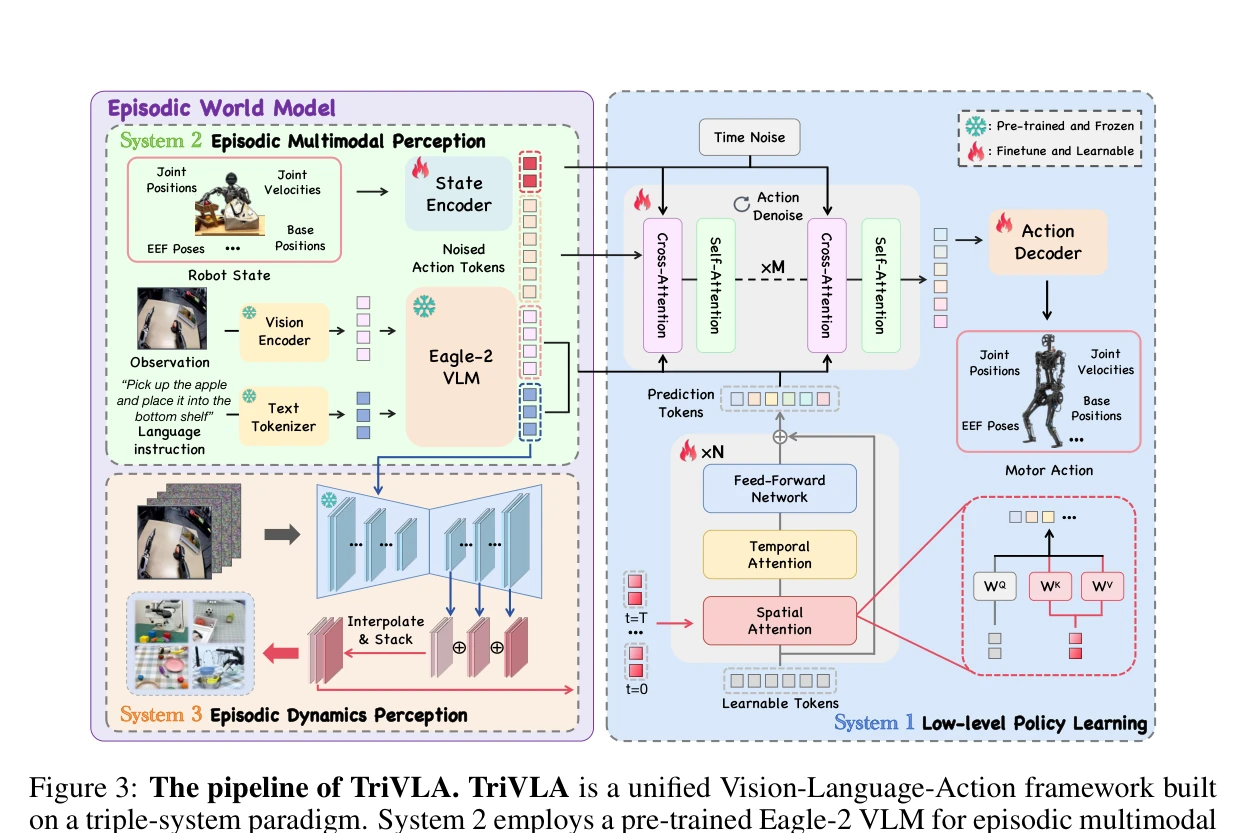
Essence
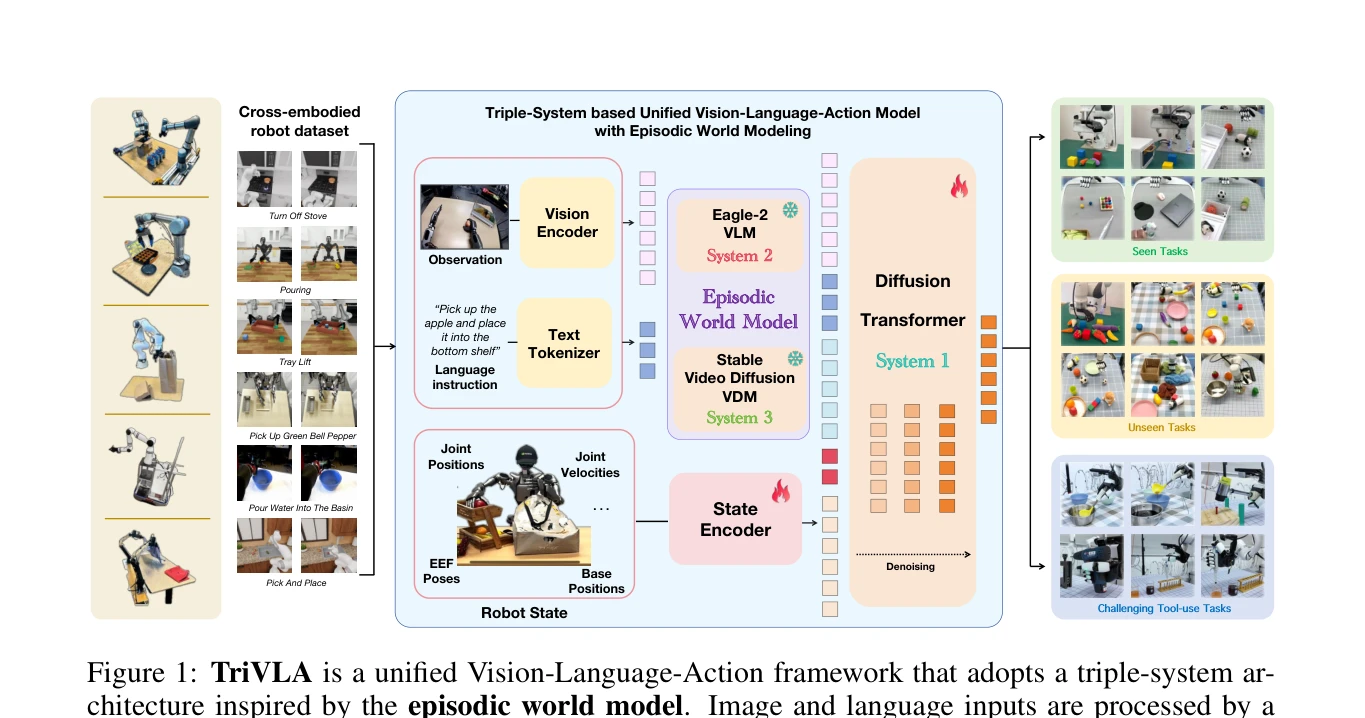
Figure 1: TriVLA is a unified Vision-Language-Action framework that adopts a triple-system ar-
인지신경과학의 에피소딕 메모리 이론에서 영감을 받아, 과거 경험의 축적·회상과 미래 동역학 예측을 통합하는 에피소딕 월드 모델을 VLA 프레임워크에 처음 도입한 TriVLA를 제안한다. Vision-Language Model, Video Diffusion Model, Policy 네트워크의 삼중 시스템 아키텍처로 구현되어 긴 지평의 조작 작업에서 문맥-인식적 행동 생성을 가능하게 한다.