저자: Qixiu Li, Yaobo Liang, Zeyu Wang, Lin Luo, Xi Chen, Mozheng Liao, Fangyun Wei, Yu Deng, Sicheng Xu, Yizhong Zhang, Xiaofan Wang, Bei Liu, Jianlong Fu, Jianmin Bao, Dong Chen, Yuanchun Shi, Jiaolong Yang, Baining Guo | 날짜: 2024-11-29 | URL: https://arxiv.org/abs/2411.19650 📄 PDF
Essence
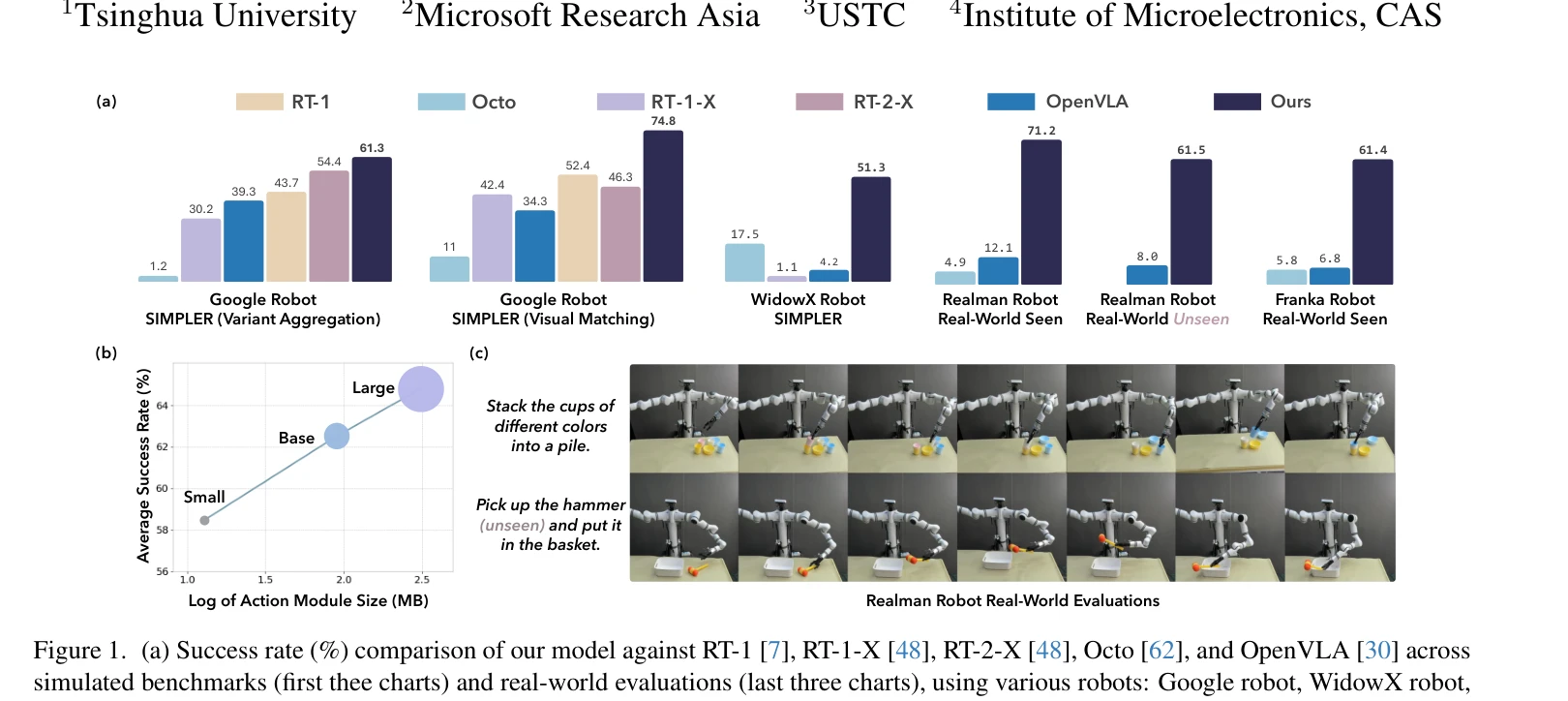
Figure 1. (a) Success rate (%) comparison of our model against RT-1 [7], RT-1-X [48], RT-2-X [48], Octo [62], and OpenVL
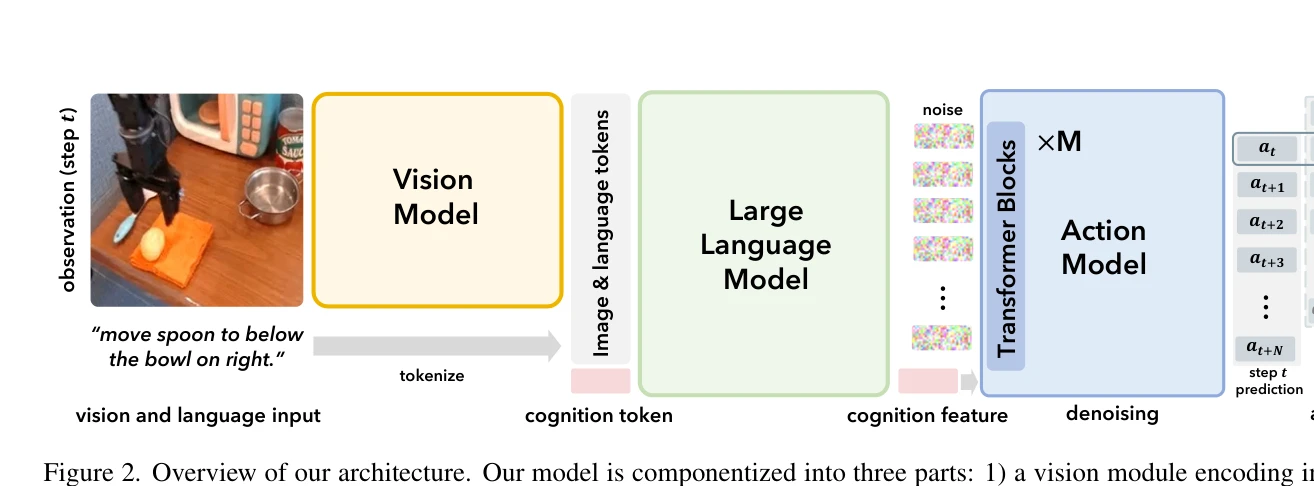
CogACT는 Vision-Language-Model을 기반으로 하되 cognition과 action을 분리하여 specializing된 diffusion action transformer 모듈을 통해 로봇 조작의 성능을 대폭 향상시킨 VLA 모델이다.
Evaluation
Novelty: 4/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: CogACT는 VLM과 diffusion action transformer의 effective synergy를 통해 로봇 조작 성능에서 significant advancement를 달성한 well-motivated 연구이며, componentized 아키텍처와 체계적인 실험을 통해 높은 원창성과 실용적 가치를 보여준다.