Essence
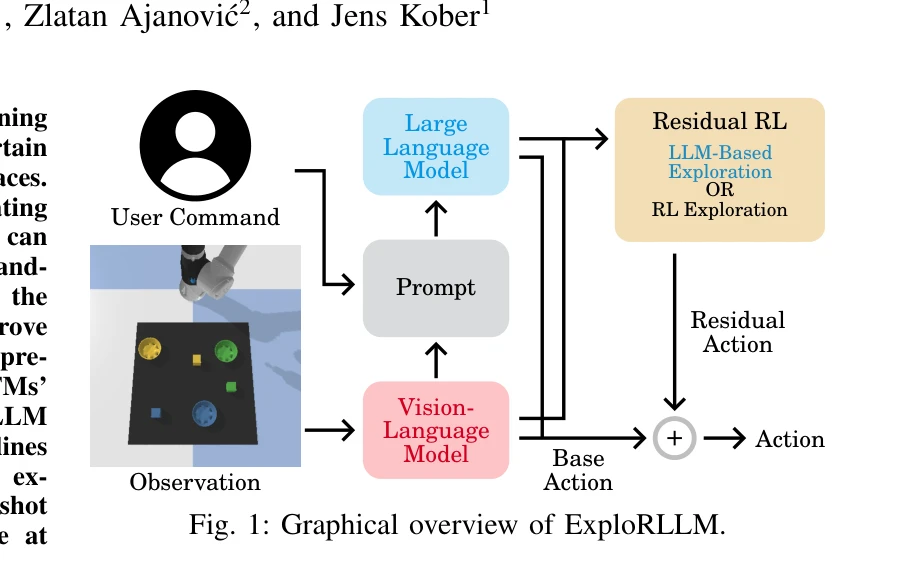
Fig. 1: Graphical overview of ExploRLLM.
ExploRLLM은 대규모 언어 모델(LLM)이 생성한 정책 코드로 RL 에이전트의 탐색을 유도하면서, 잔차 RL 에이전트가 FM의 물리적 이해 부족을 보완하는 방식으로 로봇 조작 작업의 샘플 효율성과 수렴성을 개선한다.
저자: Runyu Ma, Jelle Luijkx, Zlatan Ajanovic, Jens Kober | 날짜: 2024-03-14 | URL: https://arxiv.org/abs/2403.09583 📄 PDF
Fig. 1: Graphical overview of ExploRLLM.
ExploRLLM은 대규모 언어 모델(LLM)이 생성한 정책 코드로 RL 에이전트의 탐색을 유도하면서, 잔차 RL 에이전트가 FM의 물리적 이해 부족을 보완하는 방식으로 로봇 조작 작업의 샘플 효율성과 수렴성을 개선한다.
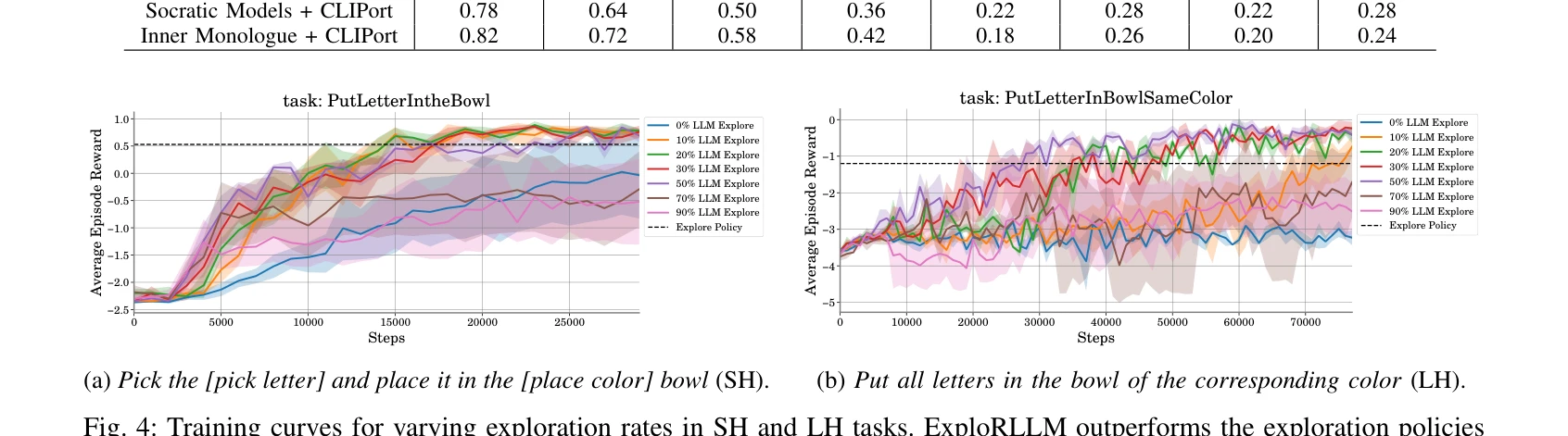
Fig. 4: Training curves for varying exploration rates in SH and LH tasks. ExploRLLM outperforms the exploration policies
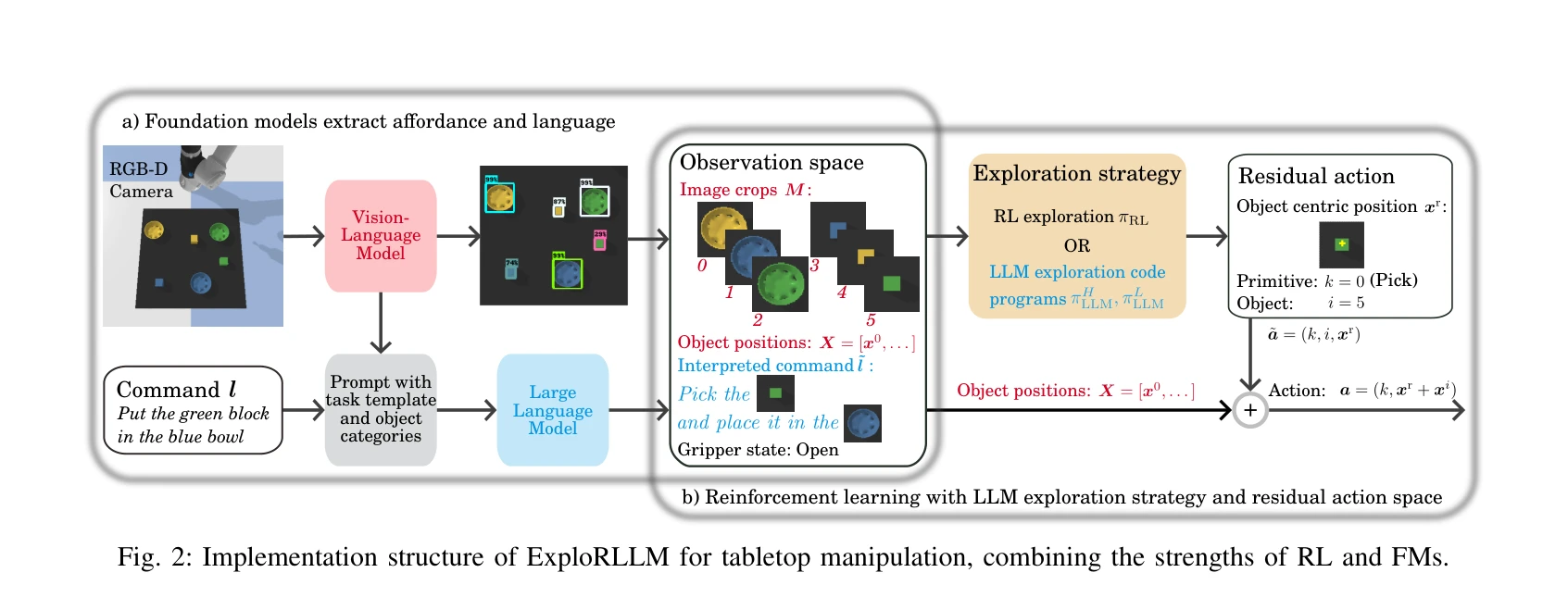
Fig. 2: Implementation structure of ExploRLLM for tabletop manipulation, combining the strengths of RL and FMs.
총평: ExploRLLM은 FM과 RL의 장점을 효과적으로 결합하여 로봇 조작의 샘플 효율성을 크게 개선하는 실용적인 방법을 제시하며, 특히 LLM 기반 탐색 전략의 혁신성과 실제 로봇에서의 zero-shot 전이 성공은 높은 가치를 가진다. 다만 평가 범위 확대와 일반화 가능성 검증이 필요하다.