Essence
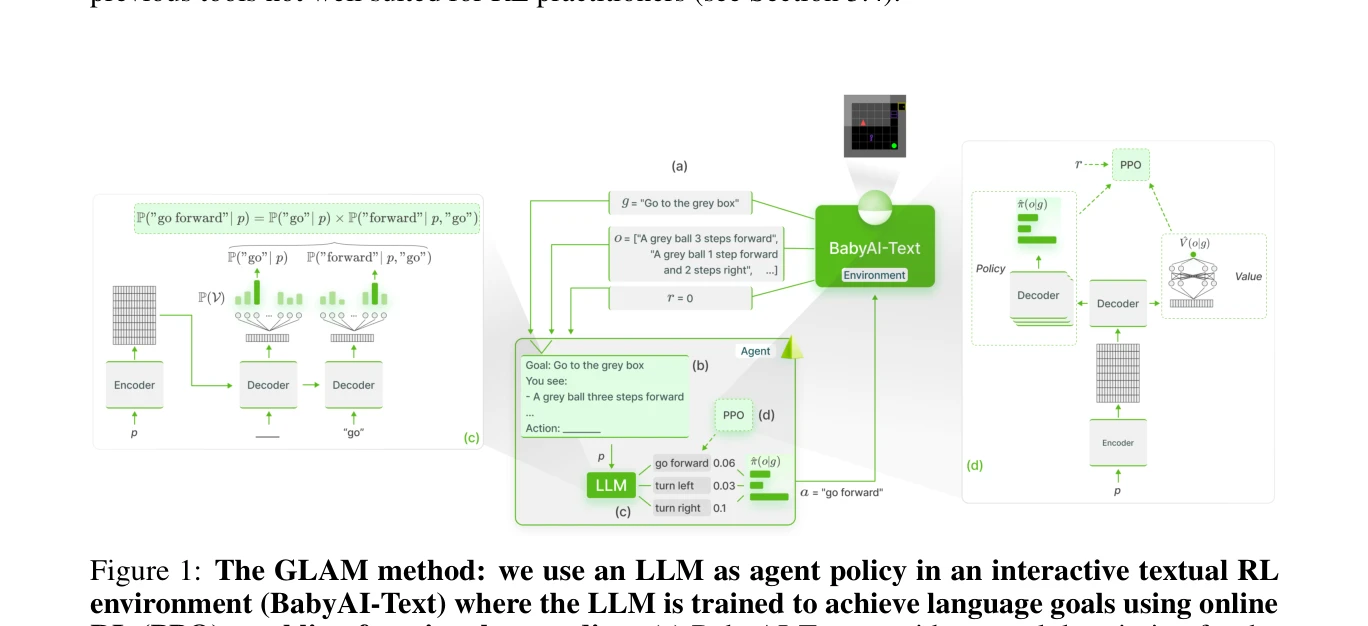
Figure 1: The GLAM method: we use an LLM as agent policy in an interactive textual RL
본 논문은 Large Language Model(LLM)을 대화형 환경에서 agent policy로 사용하며 online Reinforcement Learning으로 점진적으로 업데이트하여 functional grounding을 달성하는 GLAM 방법을 제안한다. 텍스트 기반 BabyAI 환경에서 LLM의 표본 효율성, 일반화 능력, online learning의 영향을 실증적으로 검증한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 본 논문은 LLM을 interactive environment에서 online RL로 grounding하는 중요한 첫 시도로서, 체계적인 실험과 명확한 분석을 통해 LLM 기반 policy의 sample efficiency 및 일반화 능력을 입증한다. 다만 텍스트 기반 제한 환경과 단일 모델 계열 평가라는 제약이 있으나, 공개 도구(Lamorel)와 함께 RL 커뮤니티에 기여할 가치 있는 연구이다.