Essence

Figure 1: We propose using text-guided diffusion models for data augmentation within the sphere
ROSIE는 text-to-image diffusion 모델을 이용한 inpainting을 통해 기존 로봇 조작 데이터를 의미론적으로 증강하여, 새로운 물체와 환경에 대한 로봇의 일반화 능력을 향상시키는 방법을 제안한다.
저자: Tianhe Yu, Ted Xiao, Austin Stone, Jonathan Tompson, Anthony Brohan, Su Wang, Jaspiar Singh, Clayton Tan, Dee M, Jodilyn Peralta, Brian Ichter, Karol Hausman, Fei Xia | 날짜: 2023-02-22 | URL: https://arxiv.org/abs/2302.11550 📄 PDF
Figure 1: We propose using text-guided diffusion models for data augmentation within the sphere
ROSIE는 text-to-image diffusion 모델을 이용한 inpainting을 통해 기존 로봇 조작 데이터를 의미론적으로 증강하여, 새로운 물체와 환경에 대한 로봇의 일반화 능력을 향상시키는 방법을 제안한다.

Figure 4: Augmentations of in-hand objects during manipulation. We show examples where ROSIE
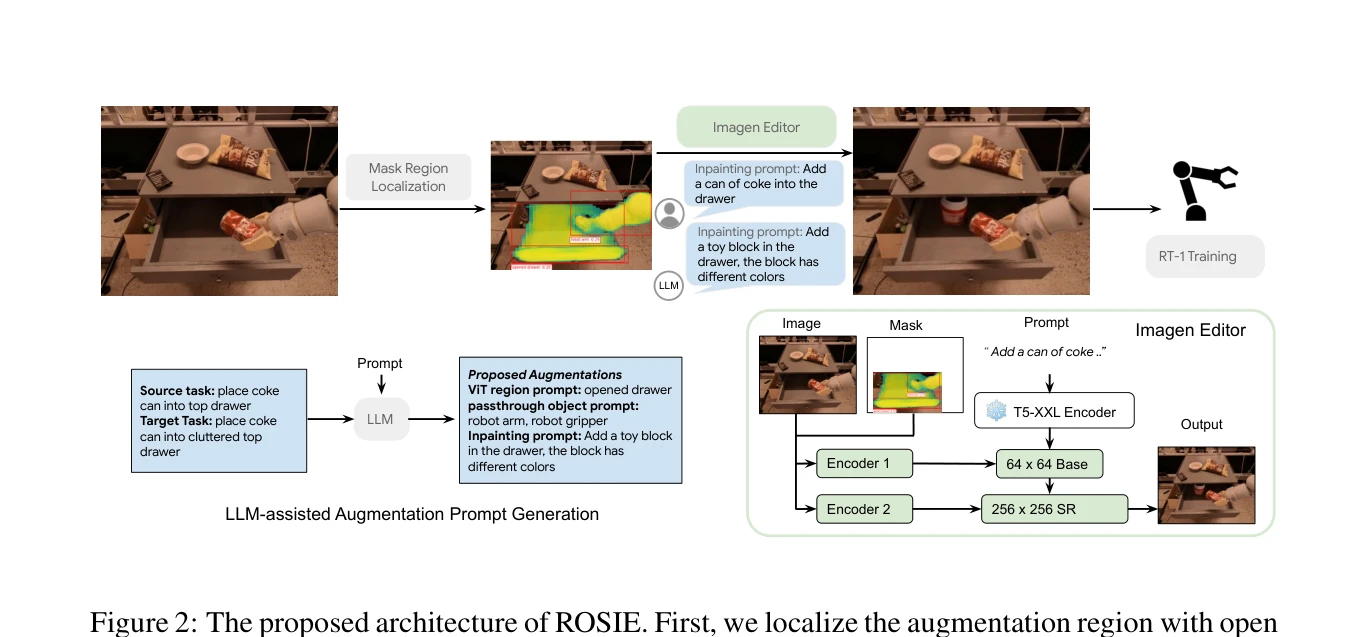
Figure 2: The proposed architecture of ROSIE. First, we localize the augmentation region with open
총평: ROSIE는 최신 text-to-image diffusion 모델을 로봇 학습에 창의적으로 적용하여 고비용의 실제 데이터 수집 없이 의미론적으로 다양한 학습 데이터를 생성하는 실용적인 방법을 제시했다. 광범위한 실험을 통해 새로운 물체 일반화, 배경/방해물 강건성, 고수준 작업 향상을 입증했으며, 로봇 학습 커뮤니티에 높은 영향을 미칠 가능성이 있다.