Essence
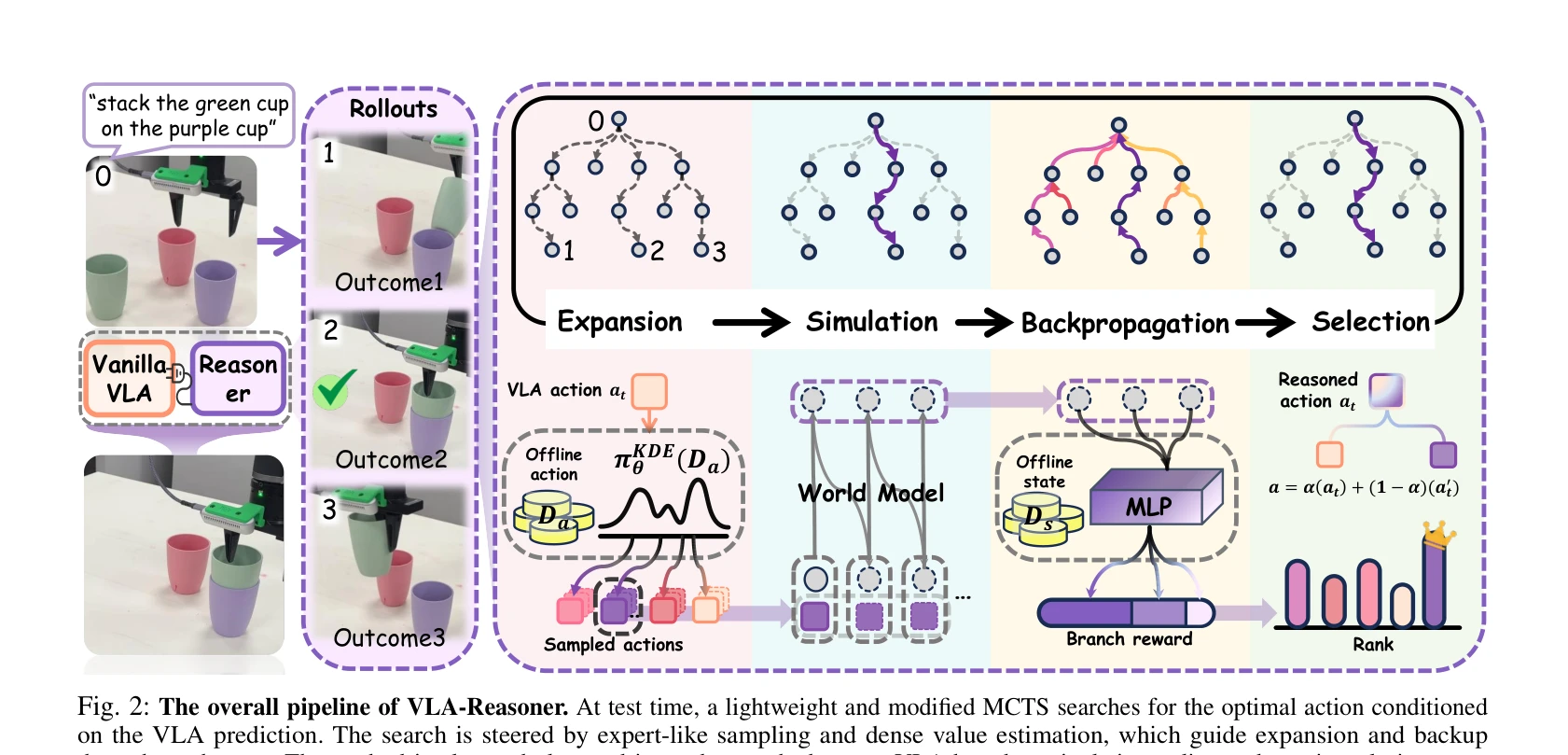
Fig. 2: The overall pipeline of VLA-Reasoner. At test time, a lightweight and modified MCTS searches for the optimal act
VLA-Reasoner는 Vision-Language-Action 모델에 test-time MCTS를 통합하여 장기 지평 로봇 조작 작업에서 누적 편차를 해결하고 미래 상태를 예측하는 플러그인 프레임워크이다.
저자: Wenkai Guo, Guanxing Lu, Haoyuan Deng, Zhenyu Wu, Yansong Tang, Ziwei Wang | 날짜: 2025-09-26 | URL: https://arxiv.org/abs/2509.22643 📄 PDF
Fig. 2: The overall pipeline of VLA-Reasoner. At test time, a lightweight and modified MCTS searches for the optimal act
VLA-Reasoner는 Vision-Language-Action 모델에 test-time MCTS를 통합하여 장기 지평 로봇 조작 작업에서 누적 편차를 해결하고 미래 상태를 예측하는 플러그인 프레임워크이다.
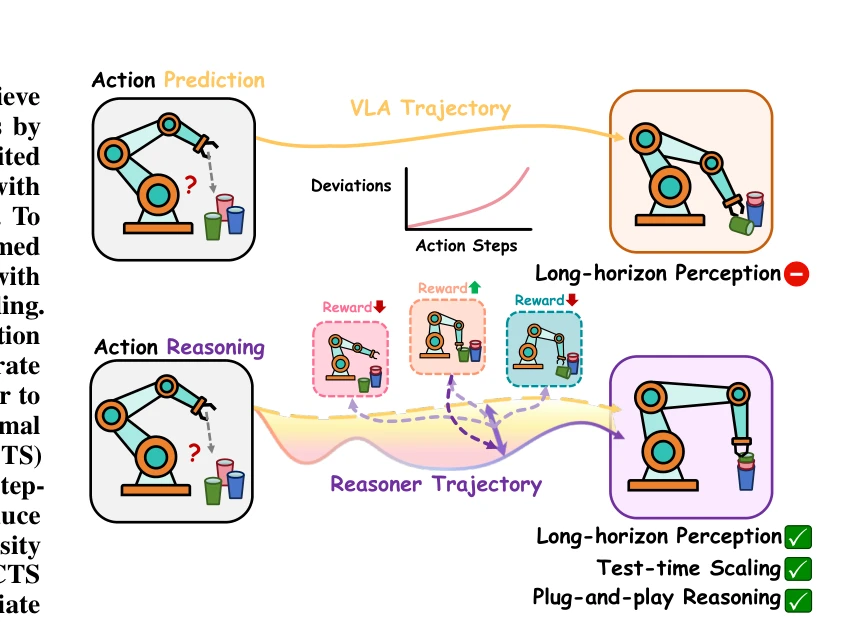
Fig. 1: VLA-Reasoner augments VLA models with test-time rea-
Fig. 2: The overall pipeline of VLA-Reasoner. At test time, a lightweight and modified MCTS searches for the optimal act
총평: VLA-Reasoner는 test-time 추론을 통해 VLA의 근본적인 단기 시야 문제를 체계적으로 해결하는 우아한 프레임워크로, KDE 샘플링과 offline value estimation의 실질적 기여와 함께 시뮬레이션과 실제 로봇에서 일관된 개선을 보여주는 의미 있는 연구이다.