저자: Chilam Cheang, Sijin Chen, Zhongren Cui, Yingdong Hu, Liqun Huang, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Xiao Ma, Hao Niu, Wenxuan Ou, Wanli Peng, Zeyu Ren, Haixin Shi, Jiawen Tian, Hongtao Wu, Xin Xiao, Yuyang Xiao, Jiafeng Xu, Yichu Yang | 날짜: 2025-07-21 | URL: https://arxiv.org/abs/2507.15493 📄 PDF
Essence

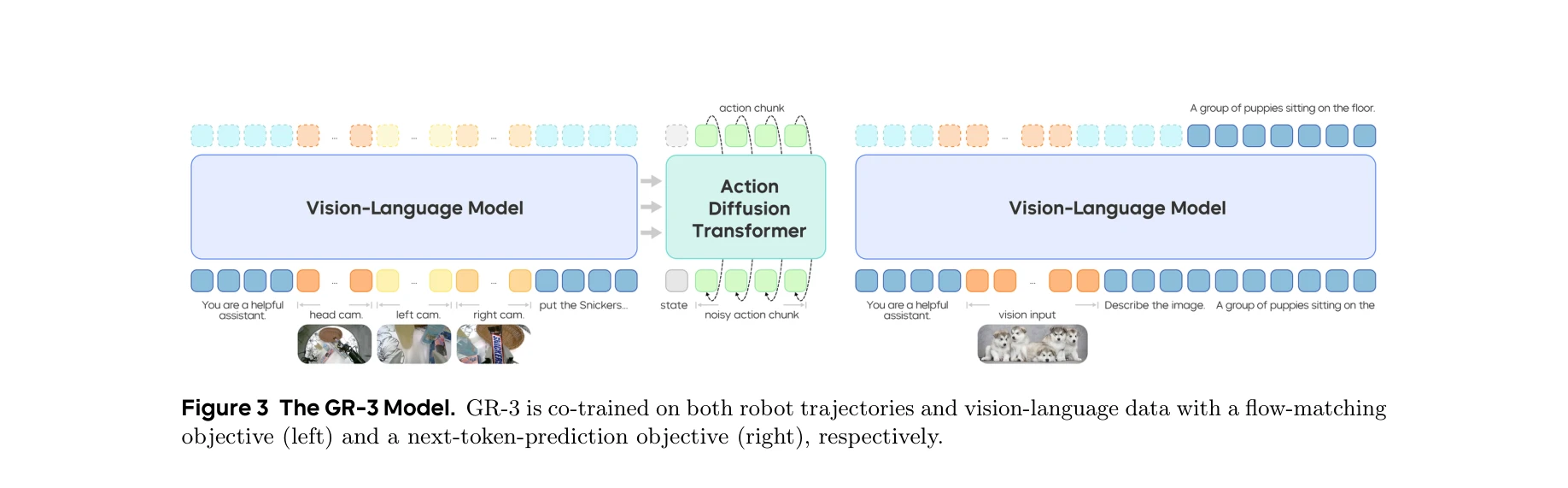
Figure 1 Overview. GR-3 is able to learn from three types of data: vision-language data, robot trajectory data,
GR-3는 vision-language-action (VLA) 모델로, 웹 규모 vision-language 데이터와 로봇 궤적 데이터의 co-training을 통해 일반화 능력, 효율적 미세조정, 장기 지평 작업 수행 능력을 갖춘 범용 로봇 정책을 구현한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: GR-3는 co-training, auxiliary supervision, VR 기반 효율적 적응 등 여러 혁신 기법을 종합한 실질적으로 견고한 VLA 모델로서, 장기 지평과 정교한 조작 작업에서 SOTA를 달성했으나, 평가 범위의 제한과 부분적 ablation 분석으로 인해 완전한 기여 명확화에는 다소 미흡하다.