Essence
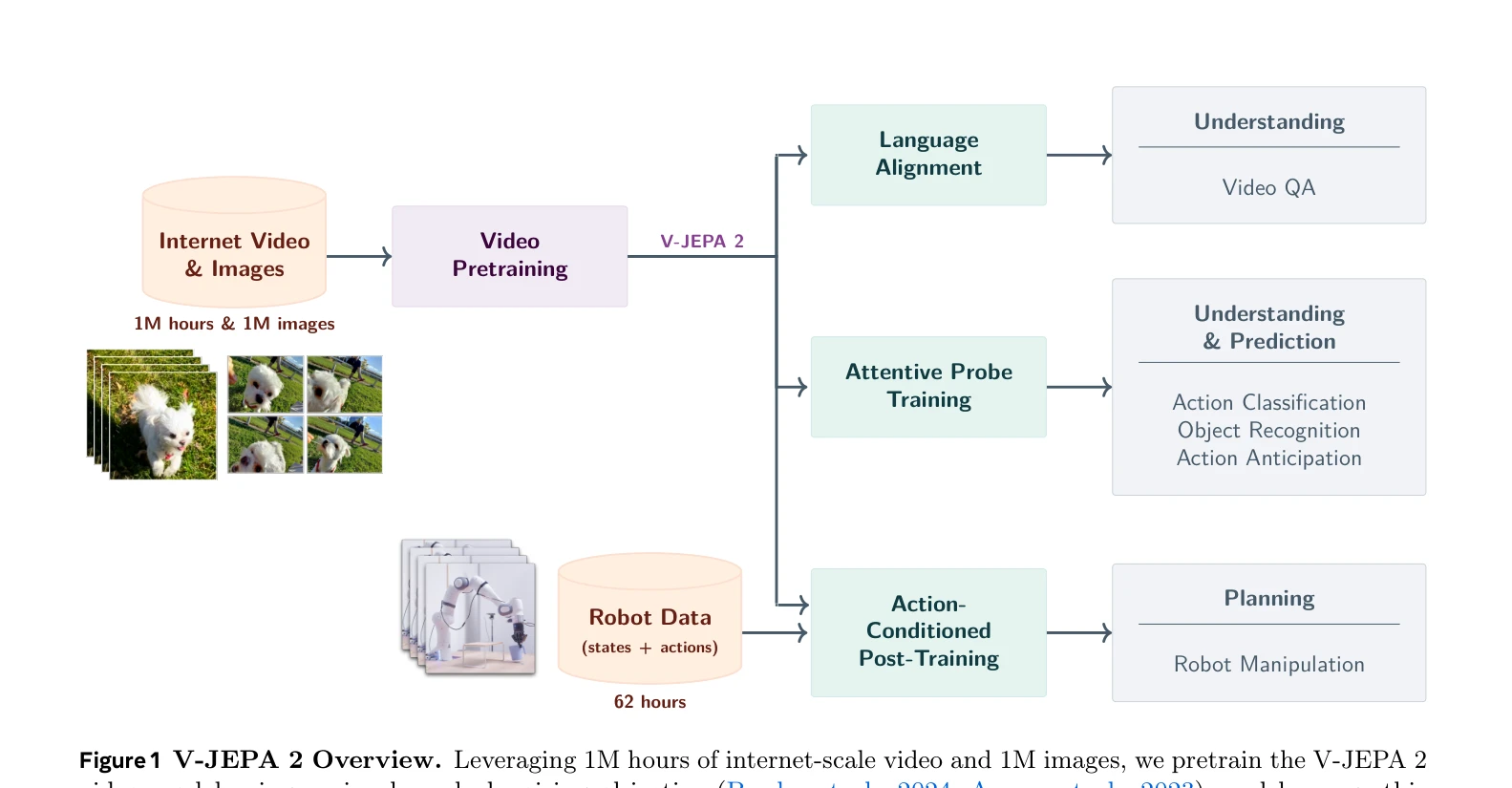
Figure 1 V-JEPA 2 Overview. Leveraging 1M hours of internet-scale video and 1M images, we pretrain the V-JEPA 2
V-JEPA 2는 1백만 시간 이상의 인터넷 규모 비디오로 사전학습한 자기지도학습 비디오 모델로, 비디오 이해·예측·로봇 계획을 모두 가능하게 한다.
저자: Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, , , Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, Sergio Arnaud, Abha Gejji, Ada Martin, Francois Robert Hogan, Daniel Dugas, Piotr Bojanowski, Vasil Khalidov, Patrick Labatut, Francisco Massa, Marc Szafraniec, Kapil Krishnakumar, Yong Li, Xiaodong Ma, Sarath Chandar, Franziska Meier, Yann LeCun, Michael Rabbat, Nicolas Ballas | 날짜: 2025-06-11 | URL: https://arxiv.org/abs/2506.09985 📄 PDF
Figure 1 V-JEPA 2 Overview. Leveraging 1M hours of internet-scale video and 1M images, we pretrain the V-JEPA 2
V-JEPA 2는 1백만 시간 이상의 인터넷 규모 비디오로 사전학습한 자기지도학습 비디오 모델로, 비디오 이해·예측·로봇 계획을 모두 가능하게 한다.
Figure 1 V-JEPA 2 Overview. Leveraging 1M hours of internet-scale video and 1M images, we pretrain the V-JEPA 2
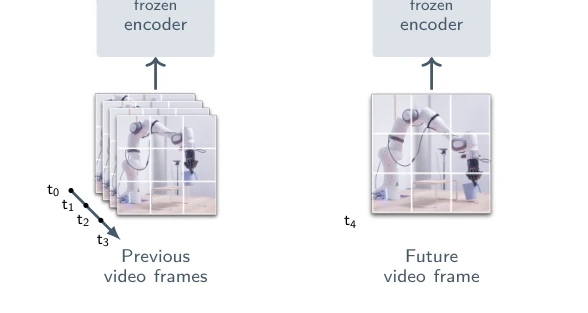
Figure 2 Multistage training. (Left) We first pretrain the V-JEPA 2 video encoder on internet-scale image and
총평: V-JEPA 2는 인터넷 규모 자기지도학습과 최소한의 로봇 상호작용 데이터를 결합하여 비디오 이해, 예측, 실제 로봇 계획을 모두 달성한 획기적 연구로, 세계 모델 기반 일반 에이전트 개발의 새로운 방향을 제시한다.