Essence
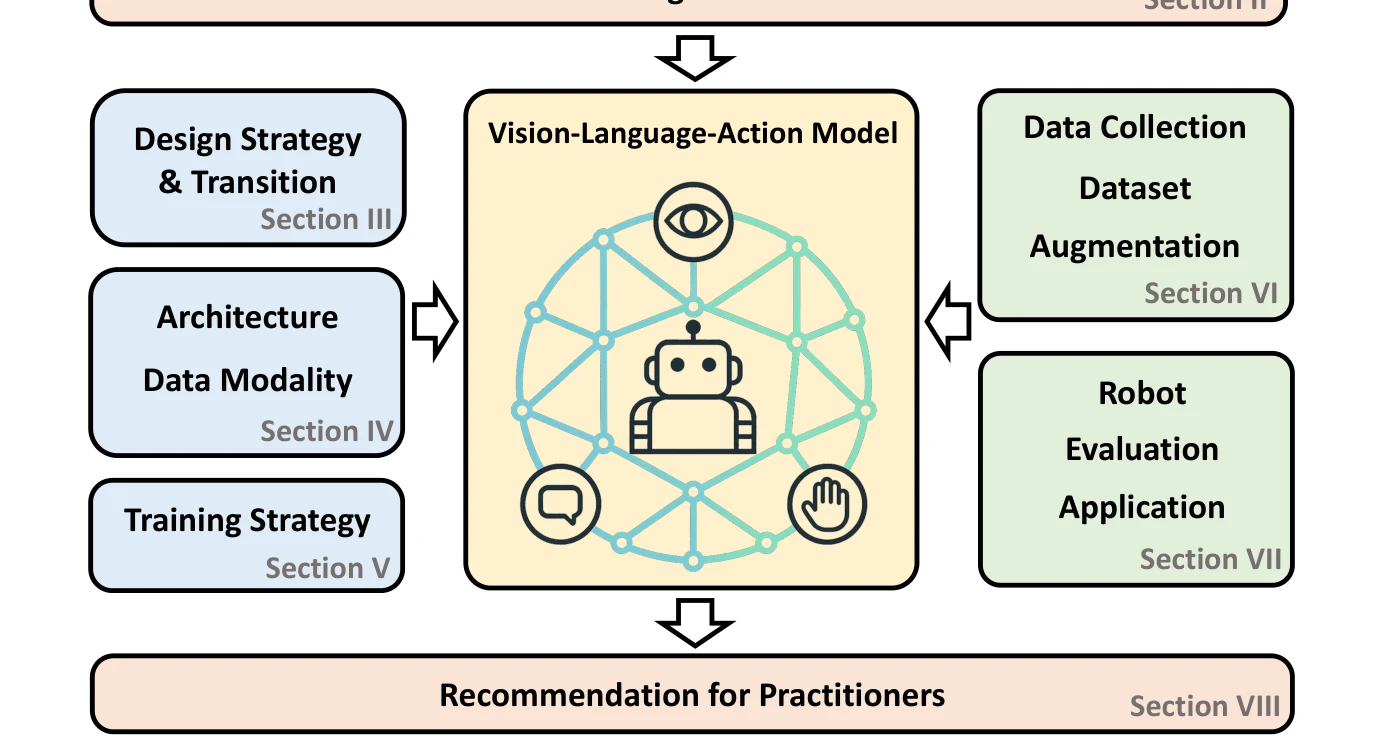
FIGURE 1. Structure of this survey. Section II outlines the key challenges in developing Vision-Language-Action (VLA) mo
Vision-Language-Action (VLA) 모델은 시각, 언어, 행동 데이터를 통합하여 로봇이 다양한 작업, 객체, 구현, 환경에 걸쳐 일반화할 수 있는 정책을 학습하는 기술이다. 이 서베이는 VLA의 아키텍처, 학습 패러다임, 데이터 수집, 실제 배포까지 포괄적인 풀스택 리뷰를 제공한다.
