Essence
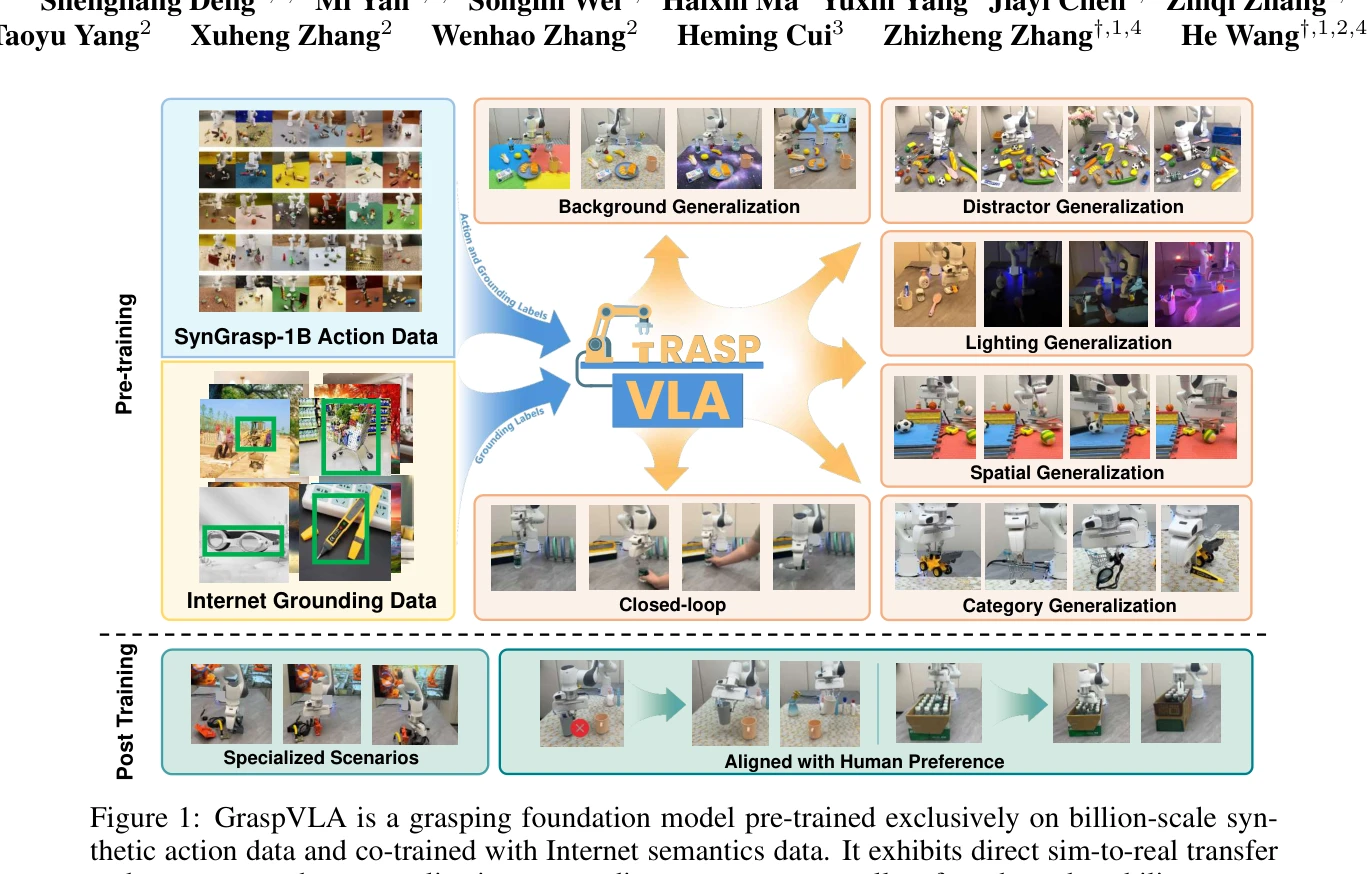
Figure 1: GraspVLA is a grasping foundation model pre-trained exclusively on billion-scale syn-
SynGrasp-1B라는 10억 프레임 규모의 합성 데이터셋을 기반으로 GraspVLA라는 Vision-Language-Action 기반 집기 모델을 제시하며, 합성 데이터만으로 사전학습하여 실세계에서 강력한 제로샷 일반화와 소수샷 적응성을 달성한다.
저자: Shengliang Deng, Mi Yan, Songlin Wei, Haixin Ma, Yuxin Yang, Jiayi Chen, Zhiqi Zhang, Taoyu Yang, Xuheng Zhang, Wenhao Zhang, Heming Cui, Zhizheng Zhang, He Wang | 날짜: 2025-05-06 | URL: https://arxiv.org/abs/2505.03233 📄 PDF
Figure 1: GraspVLA is a grasping foundation model pre-trained exclusively on billion-scale syn-
SynGrasp-1B라는 10억 프레임 규모의 합성 데이터셋을 기반으로 GraspVLA라는 Vision-Language-Action 기반 집기 모델을 제시하며, 합성 데이터만으로 사전학습하여 실세계에서 강력한 제로샷 일반화와 소수샷 적응성을 달성한다.
Figure 1: GraspVLA is a grasping foundation model pre-trained exclusively on billion-scale syn-
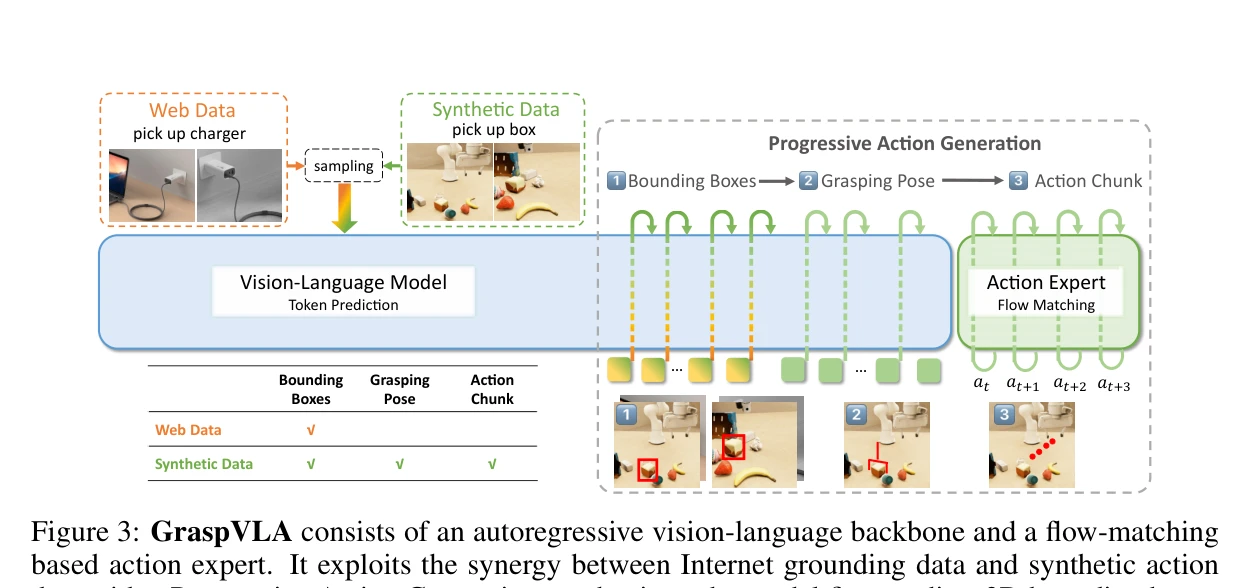
Figure 3: GraspVLA consists of an autoregressive vision-language backbone and a flow-matching
총평: 이 논문은 로봇 조작 학습을 위한 합성 데이터의 대규모 활용 가능성을 최초로 체계적으로 입증하며, 10억 프레임 규모의 고품질 데이터셋과 혁신적인 Progressive Action Generation 메커니즘을 통해 실세계 배포 가능한 강력한 기반 모델을 제시한다.