Essence
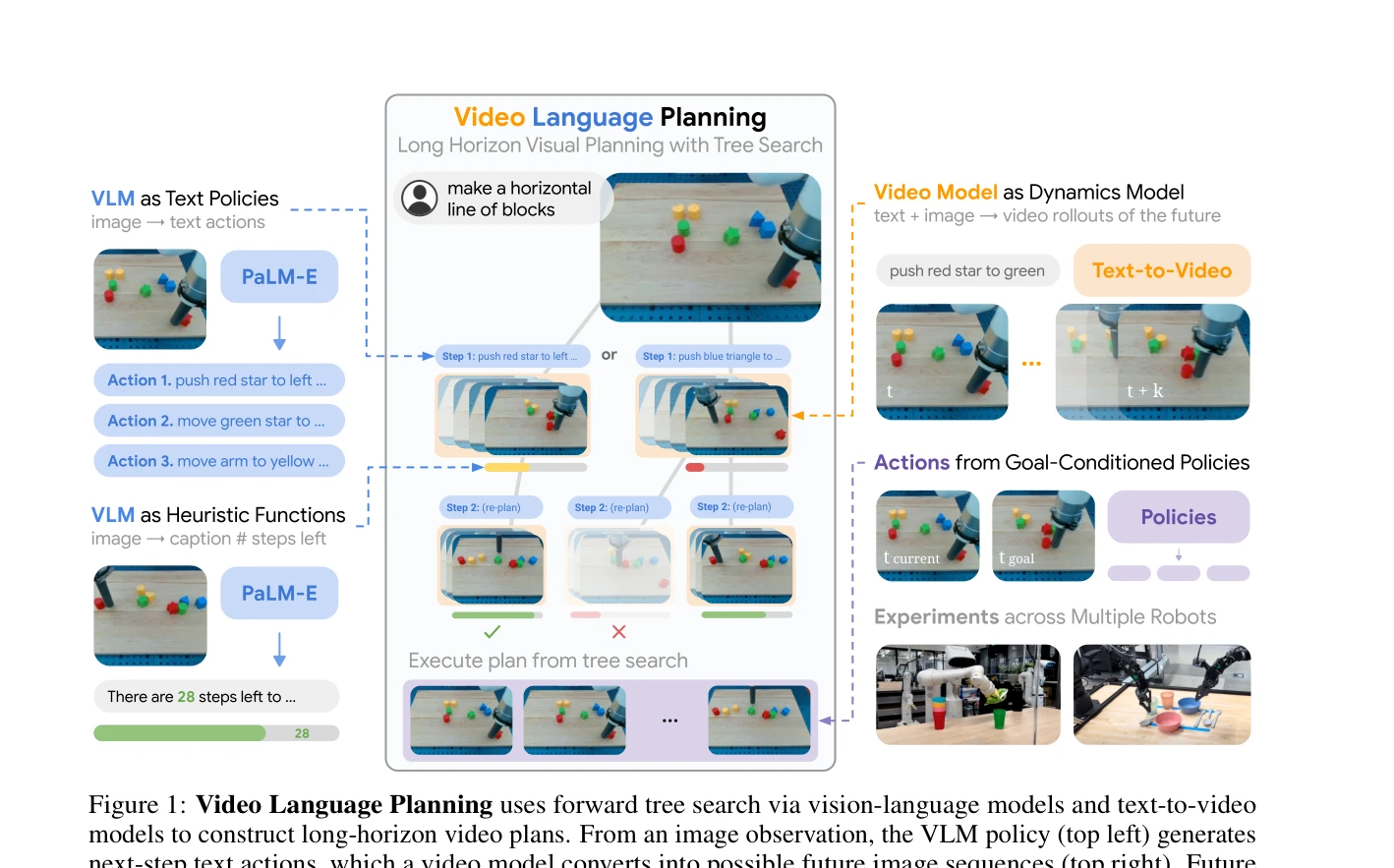
Figure 1: Video Language Planning uses forward tree search via vision-language models and text-to-video
Vision-Language Model과 Text-to-Video Model을 결합하여 트리 서치를 통해 장기 수평선 로봇 작업을 위한 상세한 비디오 계획을 생성하는 Video Language Planning(VLP) 알고리즘을 제시한다.
저자: Yilun Du, Mengjiao Yang, Pete Florence, Fei Xia, Ayzaan Wahid, Brian Ichter, Pierre Sermanet, Tianhe Yu, Pieter Abbeel, Joshua B. Tenenbaum, Leslie Kaelbling, Andy Zeng, Jonathan Tompson | 날짜: 2023-10-16 | URL: https://arxiv.org/abs/2310.10625 📄 PDF
Figure 1: Video Language Planning uses forward tree search via vision-language models and text-to-video
Vision-Language Model과 Text-to-Video Model을 결합하여 트리 서치를 통해 장기 수평선 로봇 작업을 위한 상세한 비디오 계획을 생성하는 Video Language Planning(VLP) 알고리즘을 제시한다.

Figure 3: Video Accuracy vs Planning Budget. Left: VLP scales positively with more compute budget; it is
Figure 1: Video Language Planning uses forward tree search via vision-language models and text-to-video
총평: 본 논문은 대규모 사전학습 모델의 상호보완적 강점을 영리하게 통합하여 실제 로봇 시스템에서 획기적인 성능 향상을 달성한 혁신적 연구이며, 계획 문제에 대한 현대적 재검토를 제시한다.