Essence
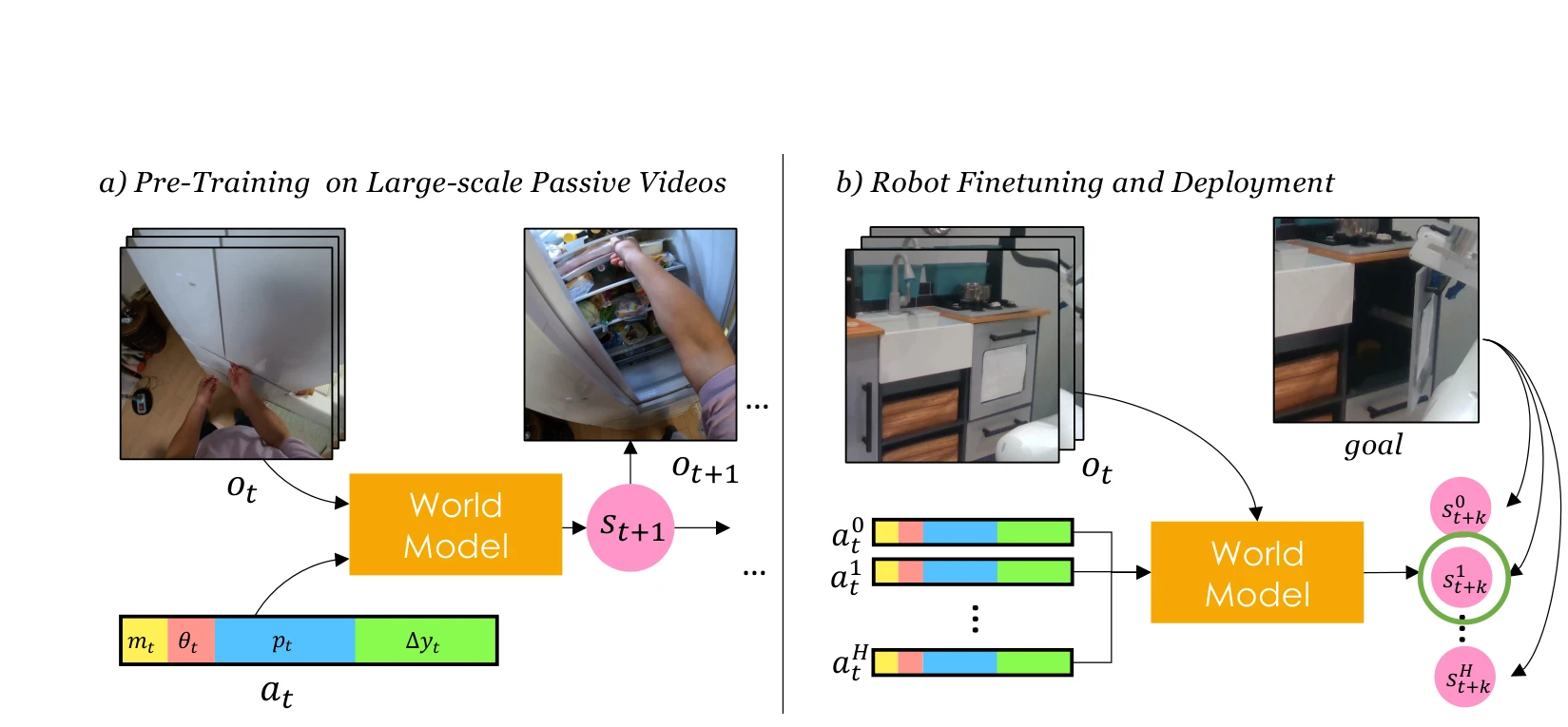
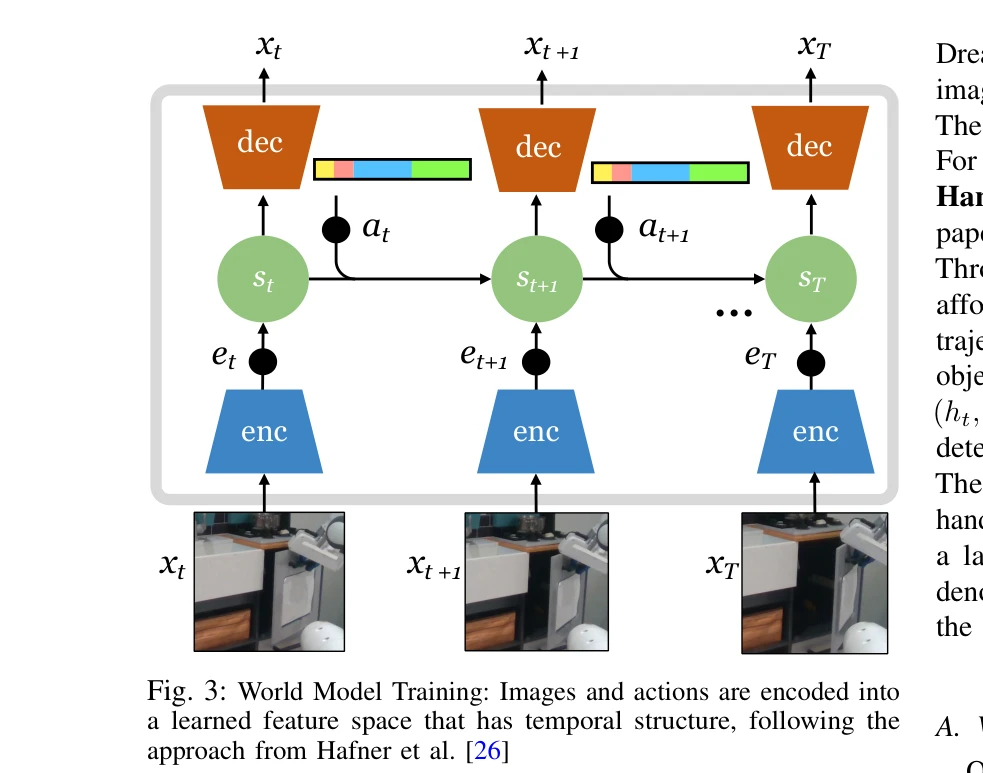
Fig. 2: Overview of SWIM. We first pre-train the world model on a large set of human videos. We finetune this on many ro
본 논문은 대규모 인간 비디오 데이터로 사전학습한 구조화된 world model을 로봇의 조작 작업에 미세조정하여, 30분 이내의 실제 상호작용으로 복잡한 조작 기술을 학습할 수 있는 SWIM 프레임워크를 제안한다.