Essence

Fig. 1: Overview of learning from human videos. Our method enables training robot policies without collecting any robot
로봇 하드웨어 없이 인간 비디오 데모만으로 로봇 정책을 학습하는 Phantom 방법을 제안하며, 데이터 편집 기법을 통해 인간-로봇 간의 embodiment gap을 극복하고 zero-shot 배포를 달성한다.
저자: Marion Lepert, Jiaying Fang, Jeannette Bohg | 날짜: 2025-03-02 | URL: https://arxiv.org/abs/2503.00779 📄 PDF
Fig. 1: Overview of learning from human videos. Our method enables training robot policies without collecting any robot
로봇 하드웨어 없이 인간 비디오 데모만으로 로봇 정책을 학습하는 Phantom 방법을 제안하며, 데이터 편집 기법을 통해 인간-로봇 간의 embodiment gap을 극복하고 zero-shot 배포를 달성한다.
Fig. 1: Overview of learning from human videos. Our method enables training robot policies without collecting any robot
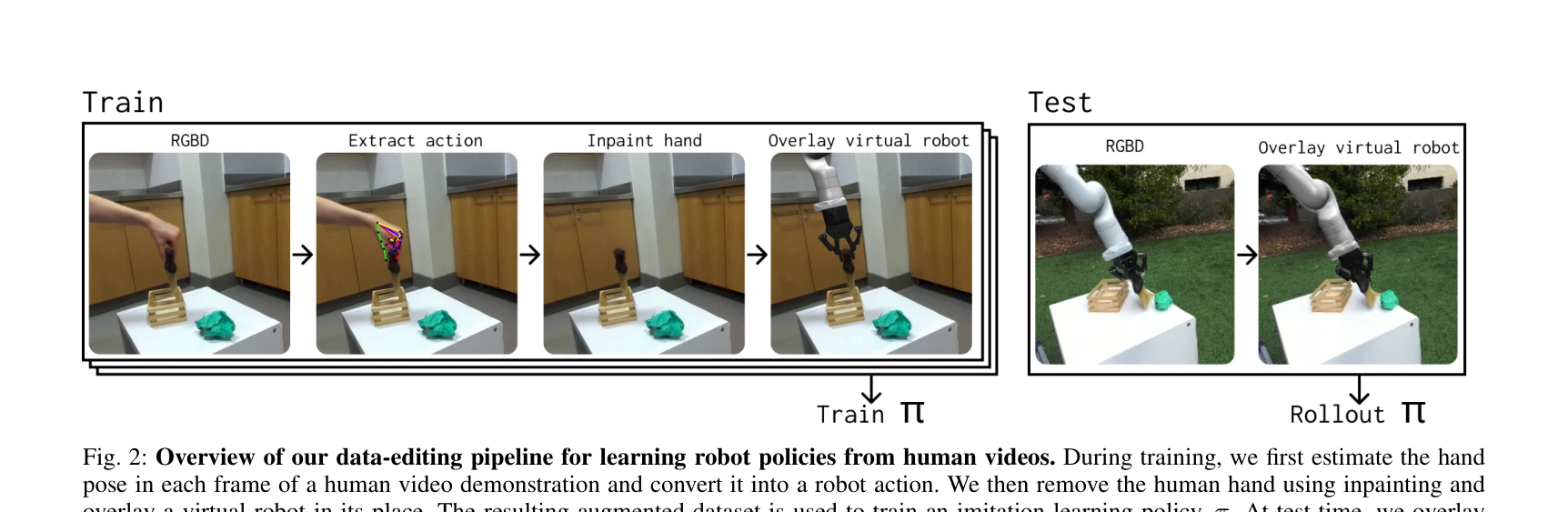
Fig. 2: Overview of our data-editing pipeline for learning robot policies from human videos. During training, we first e
총평: 본 연구는 로봇 데이터 의존성을 완전히 제거하면서도 실용적인 성과를 달성했으며, 데이터 편집 기법의 창의적 적용으로 로봇 학습의 확장성을 혁신적으로 개선한 중요한 기여다. 다만 pinch grasp 제한과 hand pose estimation에 대한 의존성이 실제 적용의 폭을 제한한다.