Essence
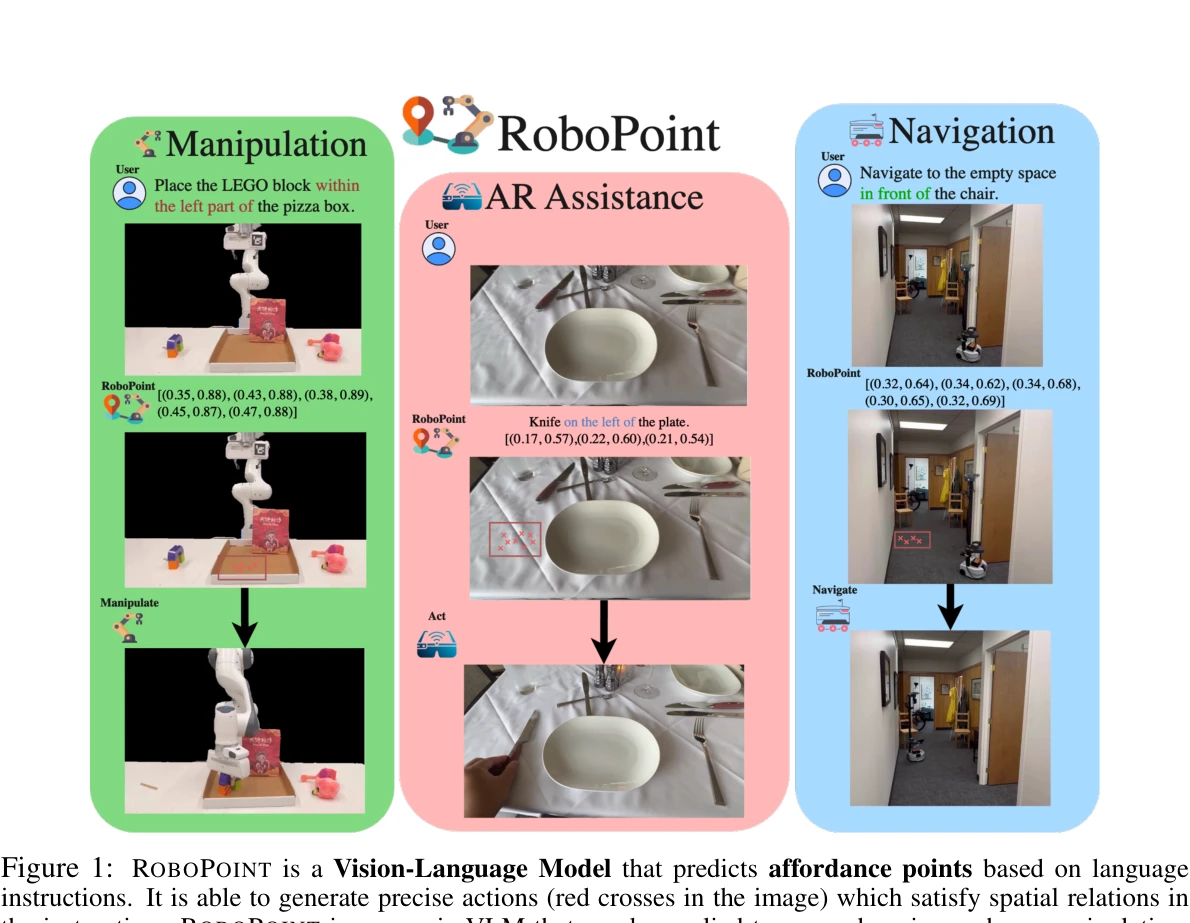
Figure 1: ROBOPOINT is a Vision-Language Model that predicts affordance points based on language
RoboPoint는 언어 지시를 받아 로봇의 정확한 행동 지점(affordance keypoint)을 예측하는 Vision-Language Model로, 자동 합성 데이터 생성 파이프라인을 통해 실제 데이터 수집 없이 학습된다.
저자: Wentao Yuan, Jiafei Duan, Valts Blukis, Wilbert Pumacay, Ranjay Krishna, Adithyavairavan Murali, Arsalan Mousavian, Dieter Fox | 날짜: 2024-06-15 | URL: https://arxiv.org/abs/2406.10721 📄 PDF
Figure 1: ROBOPOINT is a Vision-Language Model that predicts affordance points based on language
RoboPoint는 언어 지시를 받아 로봇의 정확한 행동 지점(affordance keypoint)을 예측하는 Vision-Language Model로, 자동 합성 데이터 생성 파이프라인을 통해 실제 데이터 수집 없이 학습된다.

Figure 5: Real-world manipulation evaluation. We created 7 language-conditioned manipulation tasks
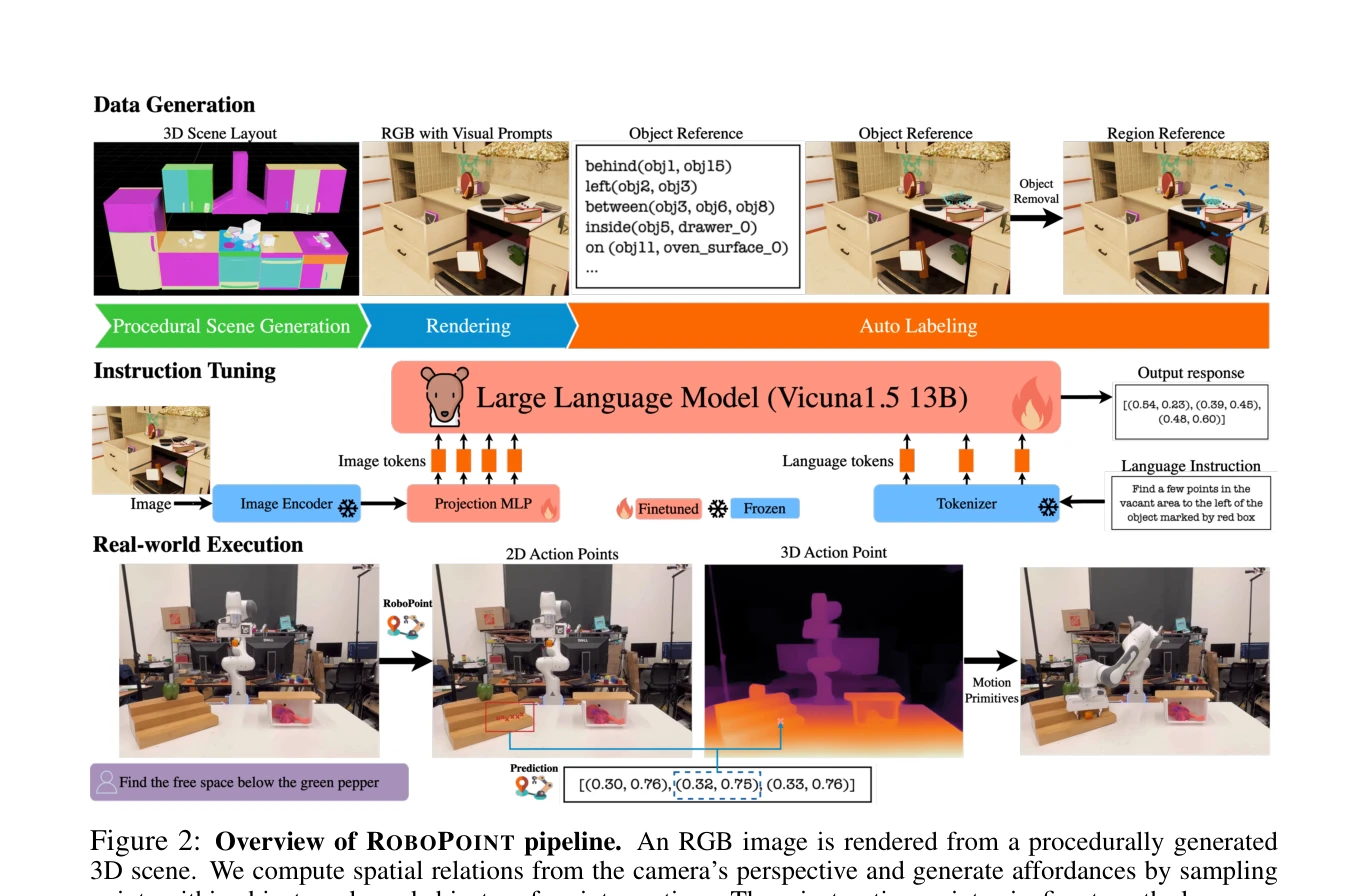
Figure 2: Overview of ROBOPOINT pipeline. An RGB image is rendered from a procedurally generated
총평: RoboPoint는 자동화된 합성 데이터 파이프라인과 점 기반 행동 공간을 결합하여 대규모 실제 데이터 수집 없이도 로봇 공간 추론을 크게 향상시킨 혁신적인 접근법이며, 조작, 네비게이션, AR 등 다양한 응용 분야의 확장성이 높지만 실제 로봇 시스템에서의 검증 강화가 필요하다.