Essence
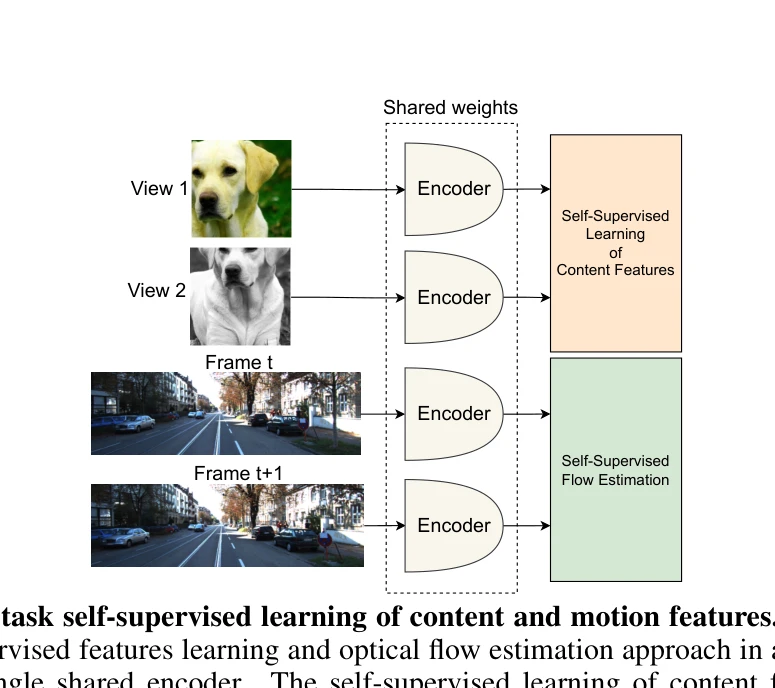
Figure 1: Multi-task self-supervised learning of content and motion features. MC-JEPA com-
MC-JEPA는 광학 흐름 추정과 콘텐츠 특성 학습을 단일 공유 인코더 내에서 결합하는 자기 지도 학습 방법으로, 두 목표가 서로 상호 이득을 주어 모션 정보를 포함하는 콘텐츠 특성을 학습한다.
저자: Adrien Bardes, Jean Ponce, Yann LeCun | 날짜: 2023-07-24 | URL: https://arxiv.org/abs/2307.12698 📄 PDF
Figure 1: Multi-task self-supervised learning of content and motion features. MC-JEPA com-
MC-JEPA는 광학 흐름 추정과 콘텐츠 특성 학습을 단일 공유 인코더 내에서 결합하는 자기 지도 학습 방법으로, 두 목표가 서로 상호 이득을 주어 모션 정보를 포함하는 콘텐츠 특성을 학습한다.
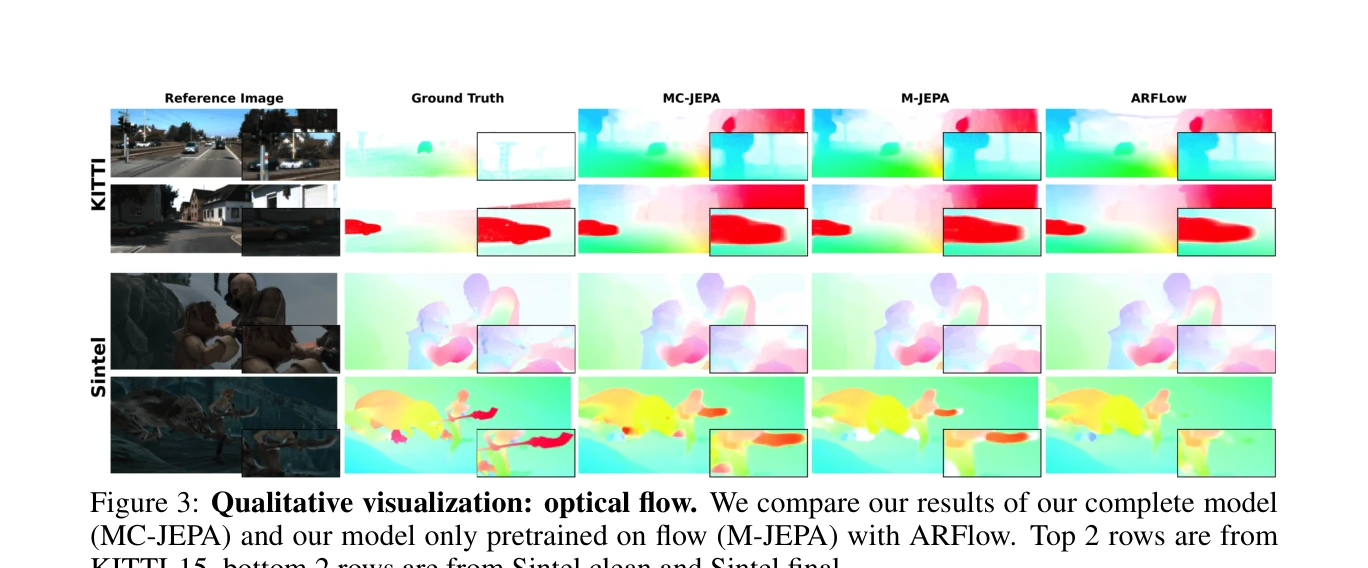
Figure 3: Qualitative visualization: optical flow. We compare our results of our complete model
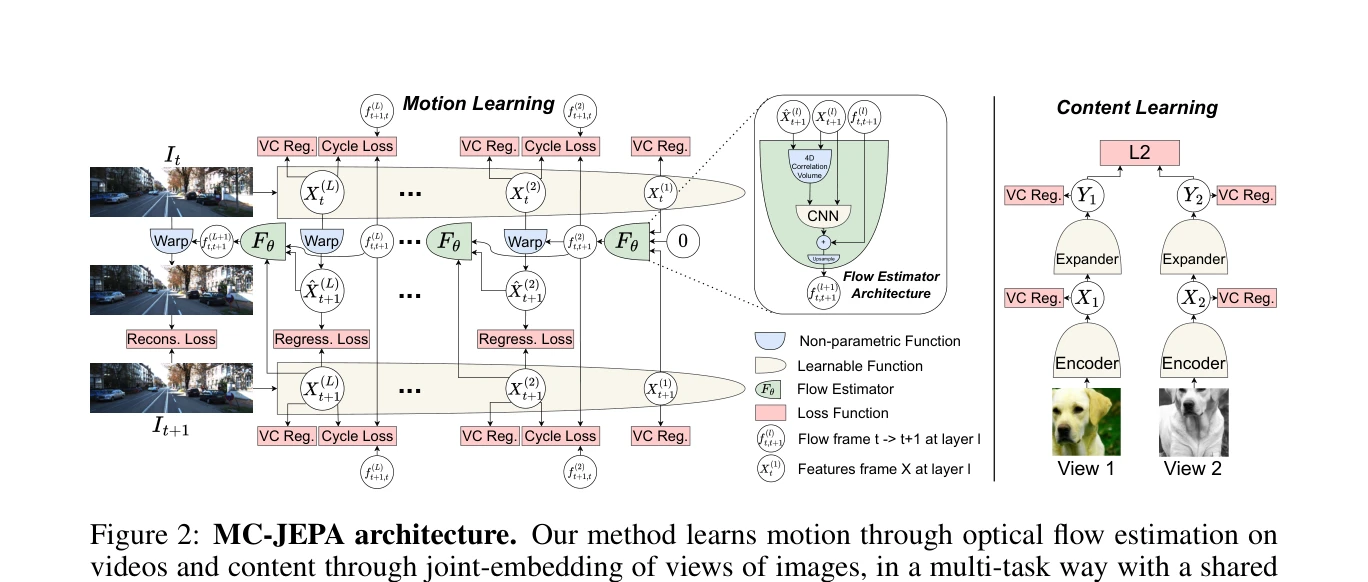
Figure 2: MC-JEPA architecture. Our method learns motion through optical flow estimation on
총평: MC-JEPA는 자기 지도 학습에서 광학 흐름과 콘텐츠 학습을 통합하는 창의적이고 기술적으로 견고한 방법으로, 다양한 시각 작업에서 단일 인코더로 우수한 성능을 달성하는 의미 있는 기여를 한다.