Essence
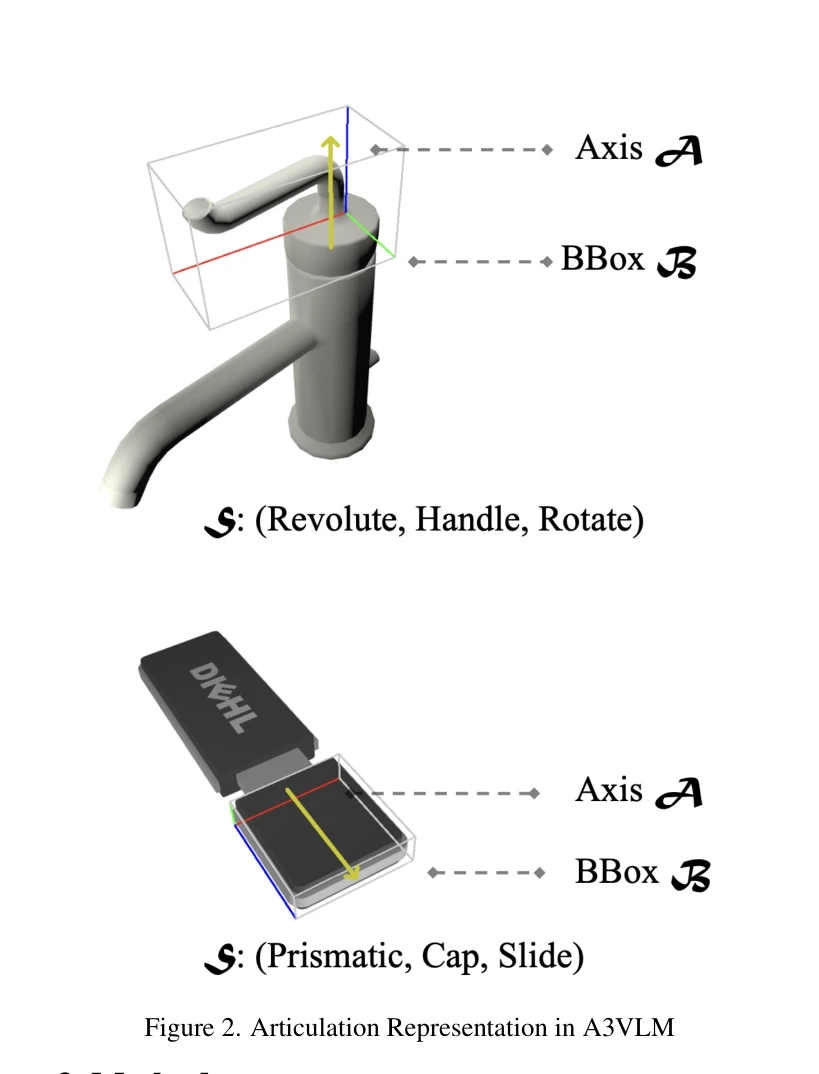
Figure 2. Articulation Representation in A3VLM
A3VLM은 로봇 중심의 행동 학습 대신 물체 중심의 관절 구조(articulation)와 행동 가능성(affordance)을 인식하는 Vision Language Model로, 비용이 많이 드는 로봇 상호작용 데이터 수집을 최소화하면서도 다양한 로봇에 적용 가능한 표현을 학습한다.
저자: Siyuan Huang, Haonan Chang, Yuhan Liu, Yimeng Zhu, Hao Dong, Peng Gao, Abdeslam Boularias, Hongsheng Li | 날짜: 2024-06-11 | URL: https://arxiv.org/abs/2406.07549 📄 PDF
Figure 2. Articulation Representation in A3VLM
A3VLM은 로봇 중심의 행동 학습 대신 물체 중심의 관절 구조(articulation)와 행동 가능성(affordance)을 인식하는 Vision Language Model로, 비용이 많이 드는 로봇 상호작용 데이터 수집을 최소화하면서도 다양한 로봇에 적용 가능한 표현을 학습한다.

Figure 1. Sequential inference with prompts. To answer the first question, A3VLM identifies the corresponding action typ
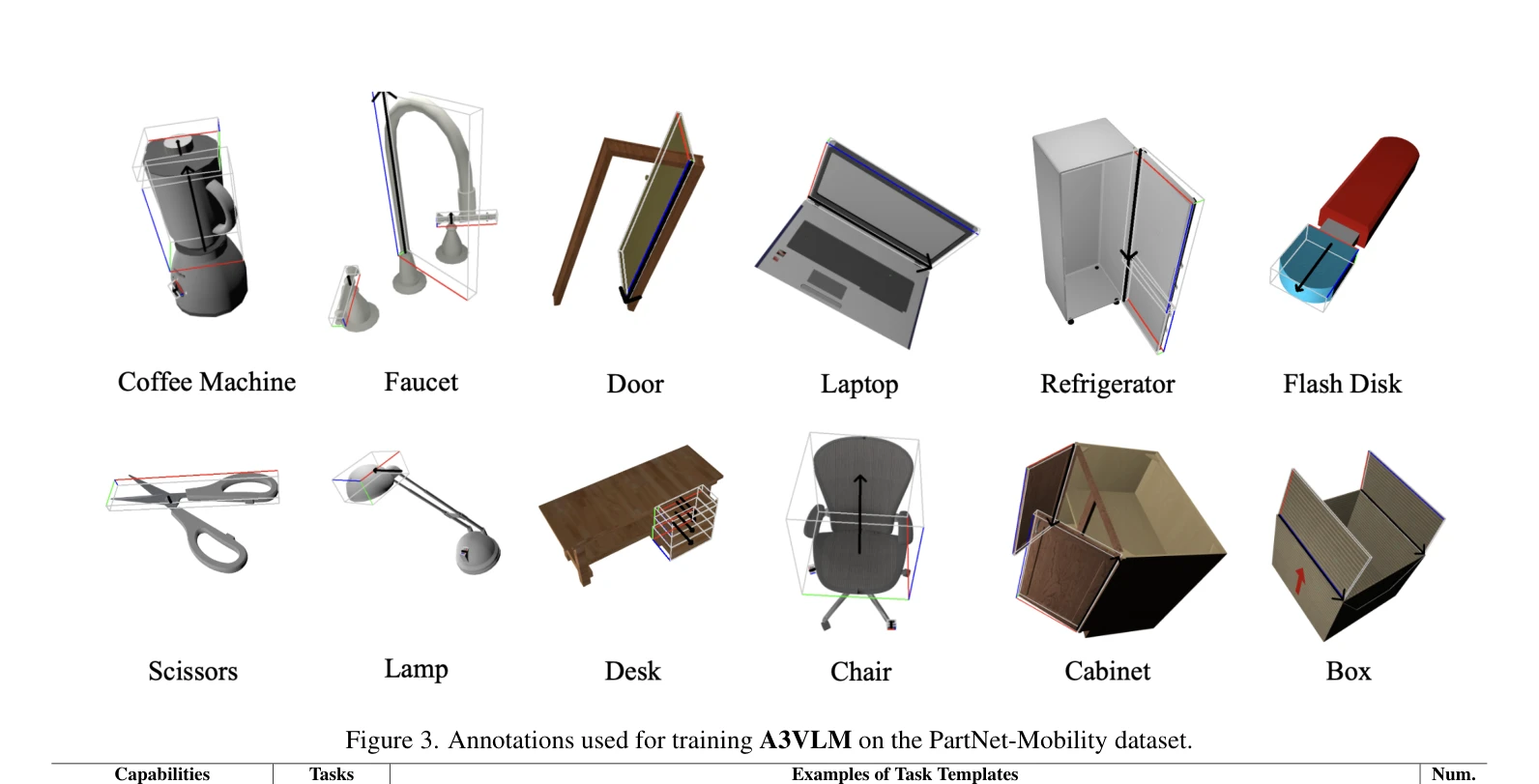
Figure 3. Annotations used for training A3VLM on the PartNet-Mobility dataset.
총평: A3VLM은 로봇 조작 문제에 대한 object-centric 패러다임을 제시하며, VLM을 활용하여 물체의 관절 구조와 행동 가능성을 효과적으로 인식하는 혁신적인 접근법이다. 비용 효율성, 로봇 독립성, 실제 환경에서의 강건성을 동시에 달성하여 실용적 가치가 높고 후속 연구에 큰 영감을 줄 수 있는 의미 있는 기여이다.