Essence
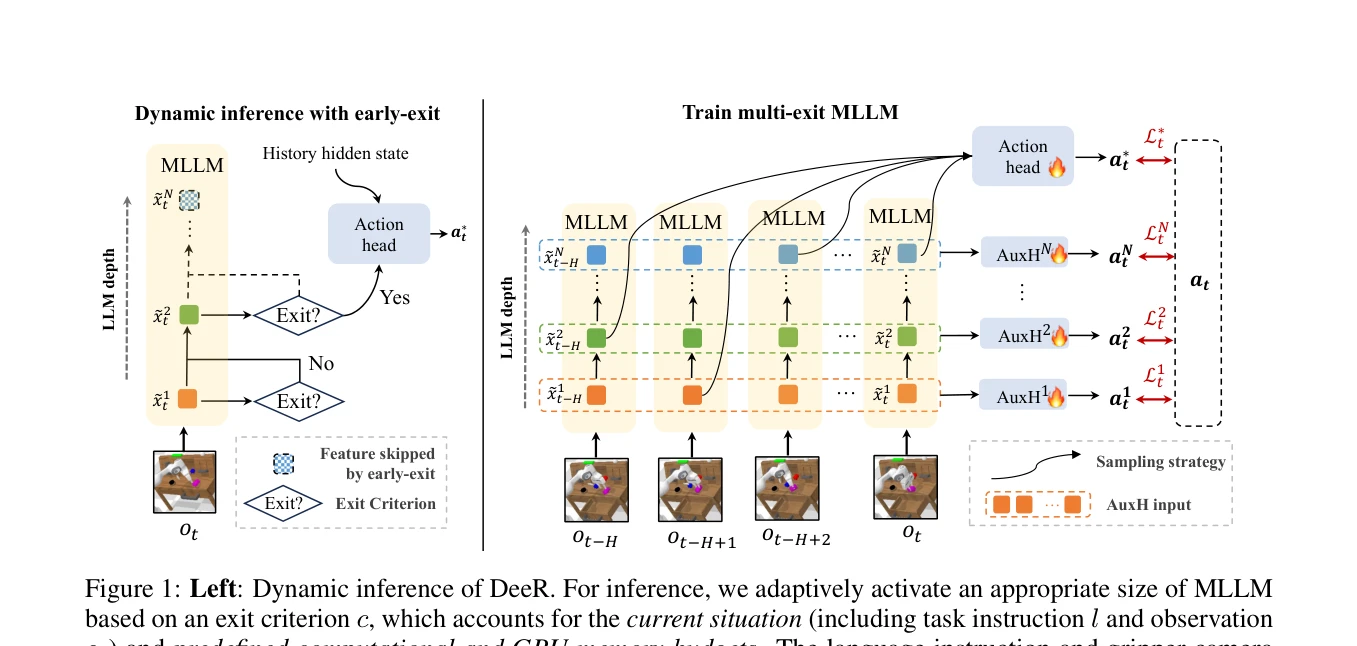
Figure 1: Left: Dynamic inference of DeeR. For inference, we adaptively activate an appropriate size of MLLM
DeeR-VLA는 멀티모달 대형 언어 모델(MLLM)의 동적 조기 종료 프레임워크로, 로봇의 각 상황에 따라 활성화되는 모델 크기를 자동으로 조정하여 계산 효율성을 5.2-6.5배 향상시킵니다.
저자: Yang Yue, Yulin Wang, Bingyi Kang, Yizeng Han, Shenzhi Wang, Shiji Song, Jiashi Feng, Gao Huang | 날짜: 2024-11-04 | URL: https://arxiv.org/abs/2411.02359 📄 PDF
Figure 1: Left: Dynamic inference of DeeR. For inference, we adaptively activate an appropriate size of MLLM
DeeR-VLA는 멀티모달 대형 언어 모델(MLLM)의 동적 조기 종료 프레임워크로, 로봇의 각 상황에 따라 활성화되는 모델 크기를 자동으로 조정하여 계산 효율성을 5.2-6.5배 향상시킵니다.
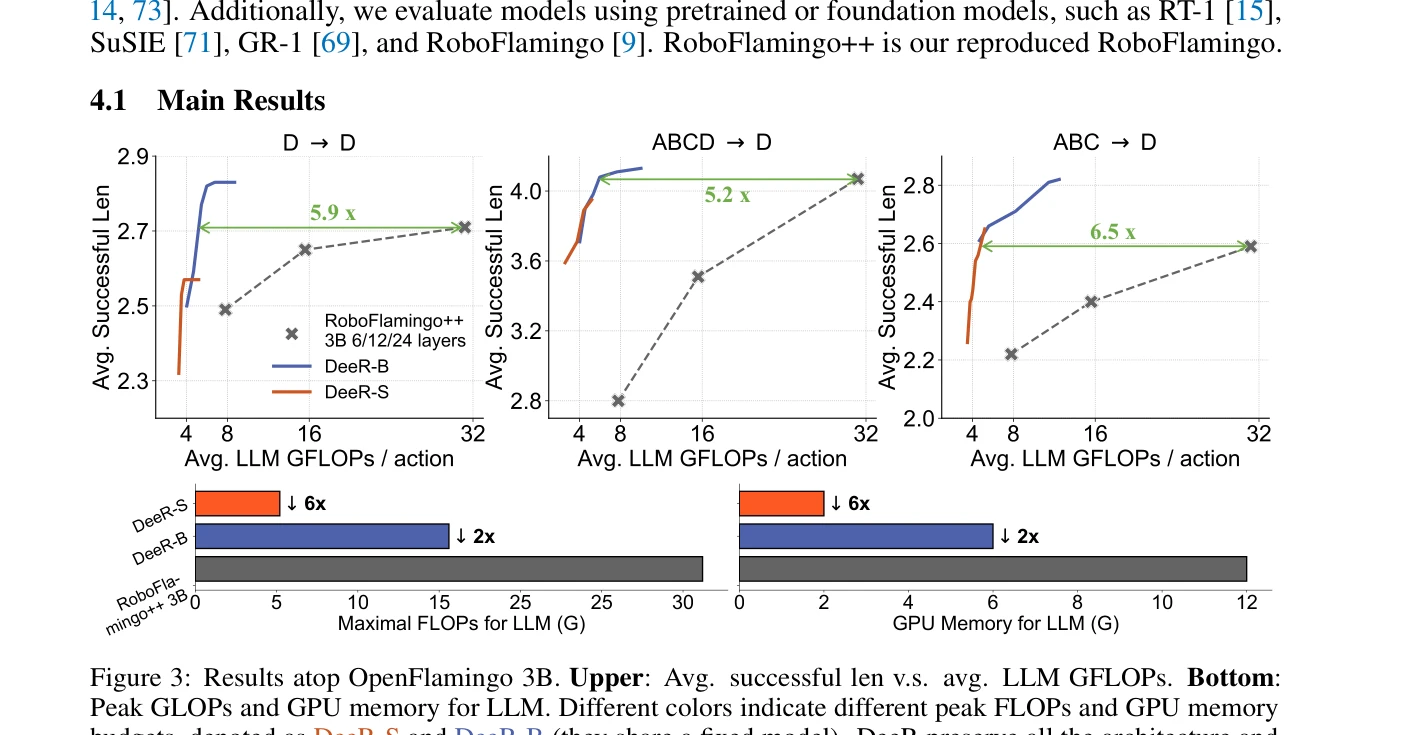
Figure 3: Results atop OpenFlamingo 3B. Upper: Avg. successful len v.s. avg. LLM GFLOPs. Bottom:
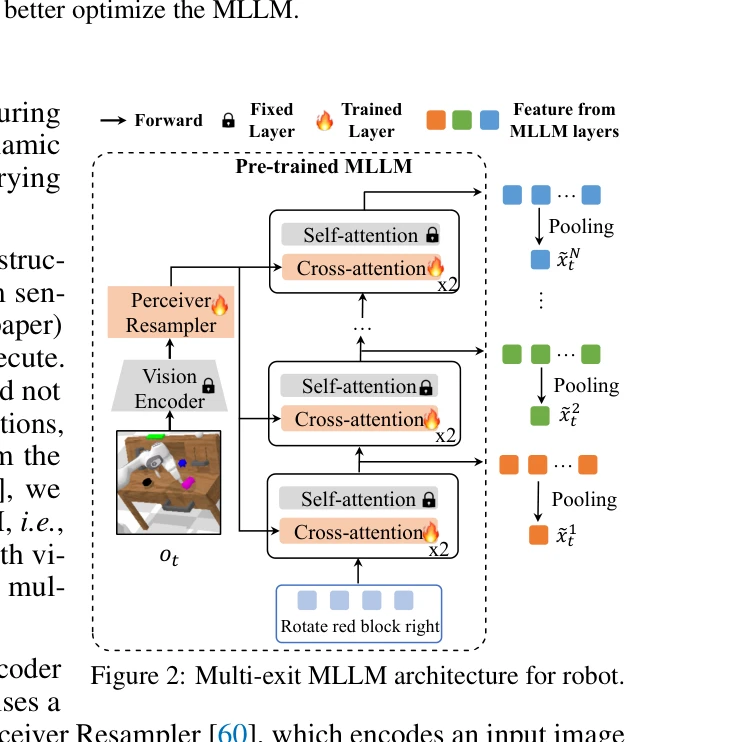
Figure 2: Multi-exit MLLM architecture for robot.
총평: DeeR-VLA는 로봇 제어를 위한 MLLM 효율화에서 실질적이고 혁신적인 접근을 제시하며, 5배 이상의 계산 비용 감소를 달성하면서도 성능을 유지하는 기술적 성과는 실제 로봇 배포 가능성을 크게 향상시킵니다.