저자: Austin Stone, Ted Xiao, Yao Lu, Keerthana Gopalakrishnan, Kuang-Huei Lee, Quan Vuong, Paul Wohlhart, Sean Kirmani, Brianna Zitkovich, Fei Xia, Chelsea Finn, Karol Hausman | 날짜: 2023-03-02 | URL: https://arxiv.org/abs/2303.00905 📄 PDF
Essence

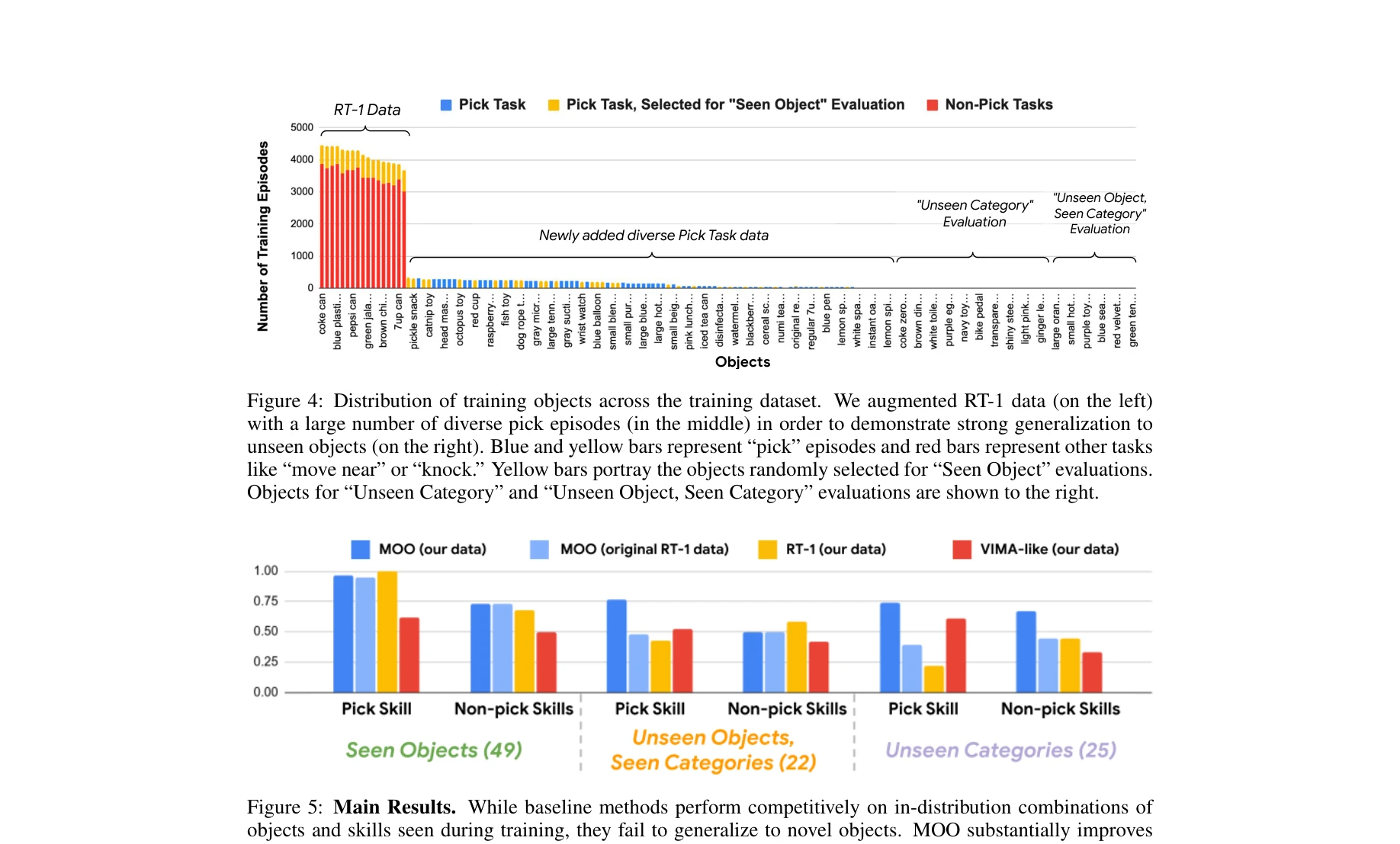
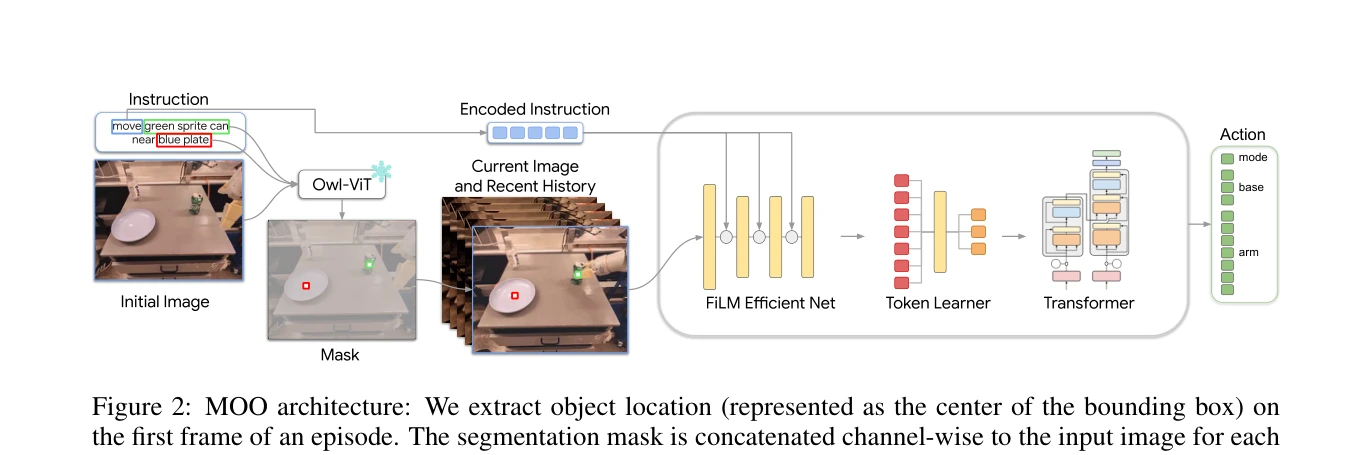
Figure 1: Overview of MOO. We train a language-conditioned policy conditioned on object locations from a
Pre-trained vision-language model(VLM)을 로봇 정책과 인터페이싱하여 로봇이 직접 경험하지 못한 새로운 물체 카테고리에 대한 지시를 따를 수 있도록 하는 MOO(Manipulation of Open-World Objects) 방법을 제안한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 본 논문은 pre-trained VLM을 로봇 조작에 실질적으로 통합하여 의미론적 일반화를 달성한 중요한 기여이며, 실제 로봇 실험과 다중 모달리티 확장을 통해 실용성을 입증했다.