Essence
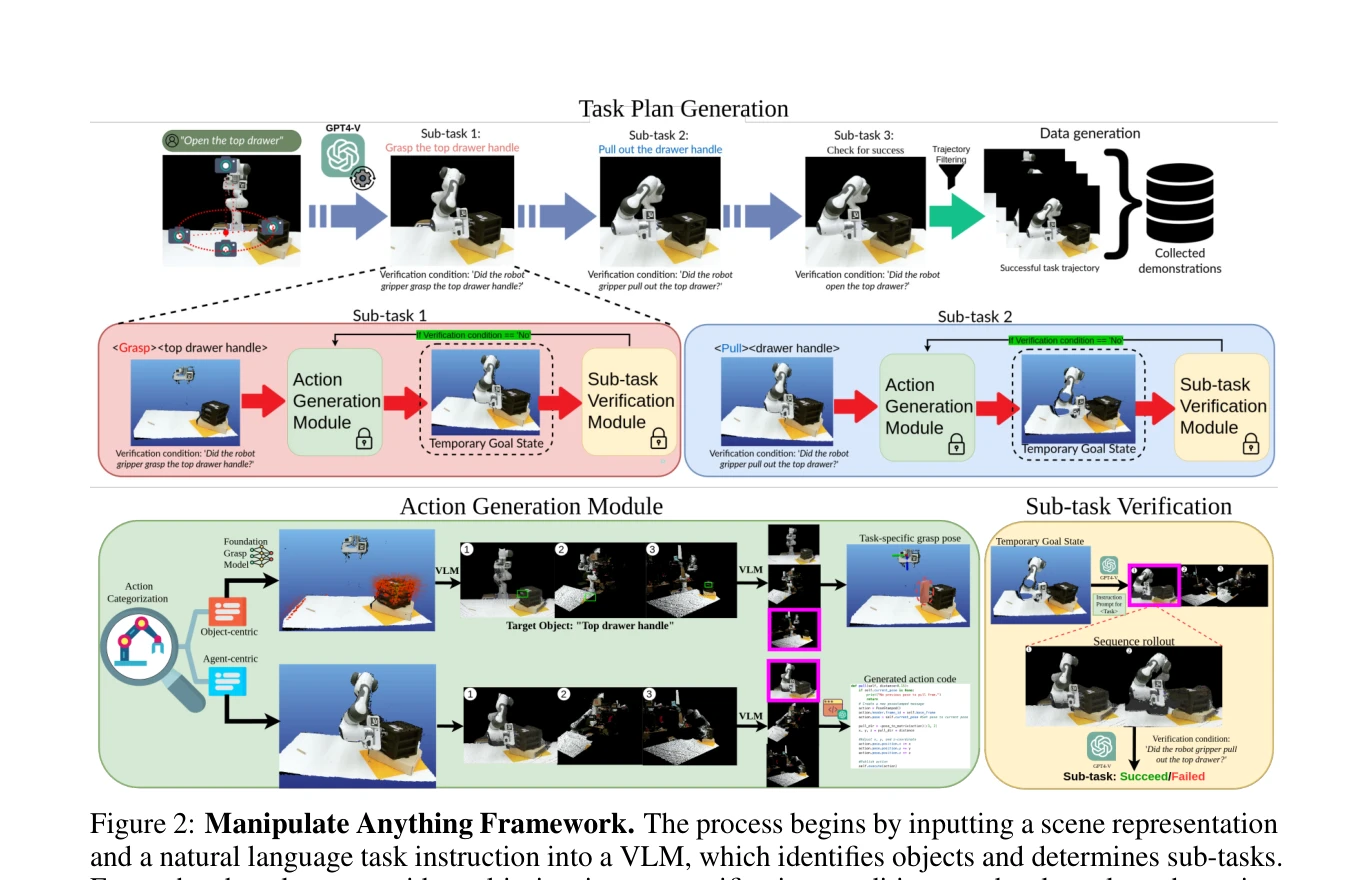
Figure 2: Manipulate Anything Framework. The process begins by inputting a scene representation
Vision-Language Model을 활용하여 실제 로봇 환경에서 특권 정보나 사전 설계된 스킬 없이 자동으로 로봇 조작 시연 데이터를 생성하는 Manipulate-Anything 프레임워크를 제안한다.
저자: Jiafei Duan, Wentao Yuan, Wilbert Pumacay, Yi Ru Wang, Kiana Ehsani, Dieter Fox, Ranjay Krishna | 날짜: 2024-06-27 | URL: https://arxiv.org/abs/2406.18915 📄 PDF
Figure 2: Manipulate Anything Framework. The process begins by inputting a scene representation
Vision-Language Model을 활용하여 실제 로봇 환경에서 특권 정보나 사전 설계된 스킬 없이 자동으로 로봇 조작 시연 데이터를 생성하는 Manipulate-Anything 프레임워크를 제안한다.
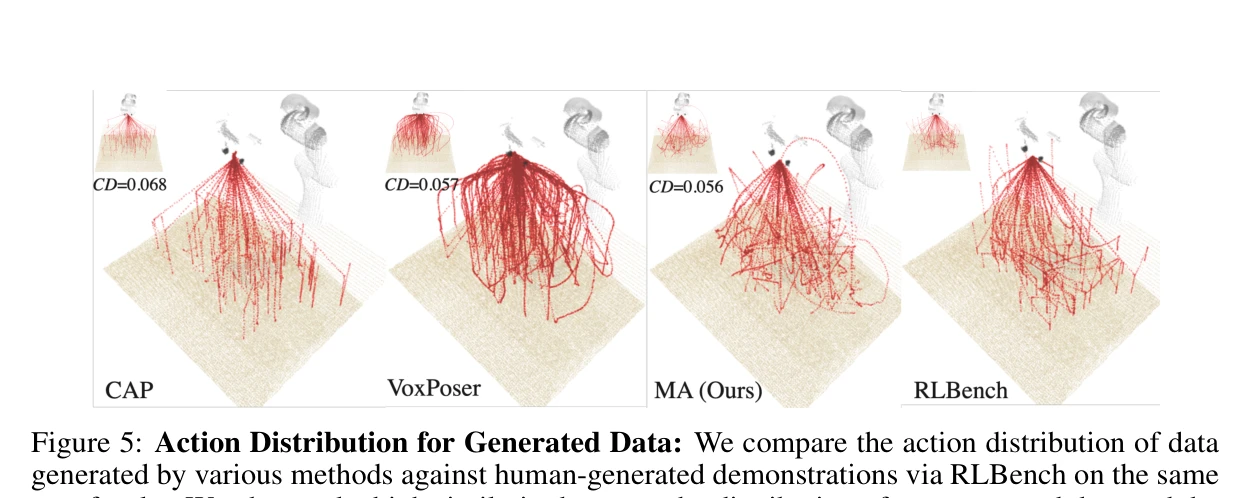
Figure 5: Action Distribution for Generated Data: We compare the action distribution of data
Figure 2: Manipulate Anything Framework. The process begins by inputting a scene representation
총평: Manipulate-Anything은 VLM의 상식적 지식을 체계적으로 활용하여 실제 로봇 환경에서 확장 가능한 자동 데이터 생성을 달성한 혁신적인 프레임워크이며, 생성된 데이터가 인간 시연보다 우수한 정책을 학습시킬 수 있다는 놀라운 결과는 로봇 학습의 미래를 큰 변화시킬 수 있는 잠재력을 시사한다.