Essence

Figure 1: Pre-Training Reusable Representations for Robot Manipulation (R3M): We pre-train a visual
Ego4D 인간 비디오 데이터셋에서 pre-train한 R3M 시각 표현을 제안하여, 로봇 조작 작업의 data-efficient 학습을 가능하게 한다.
저자: Suraj Nair, Aravind Rajeswaran, Vikash Kumar, Chelsea Finn, Abhinav Gupta | 날짜: 2022-03-23 | URL: https://arxiv.org/abs/2203.12601 📄 PDF
Figure 1: Pre-Training Reusable Representations for Robot Manipulation (R3M): We pre-train a visual
Ego4D 인간 비디오 데이터셋에서 pre-train한 R3M 시각 표현을 제안하여, 로봇 조작 작업의 data-efficient 학습을 가능하게 한다.
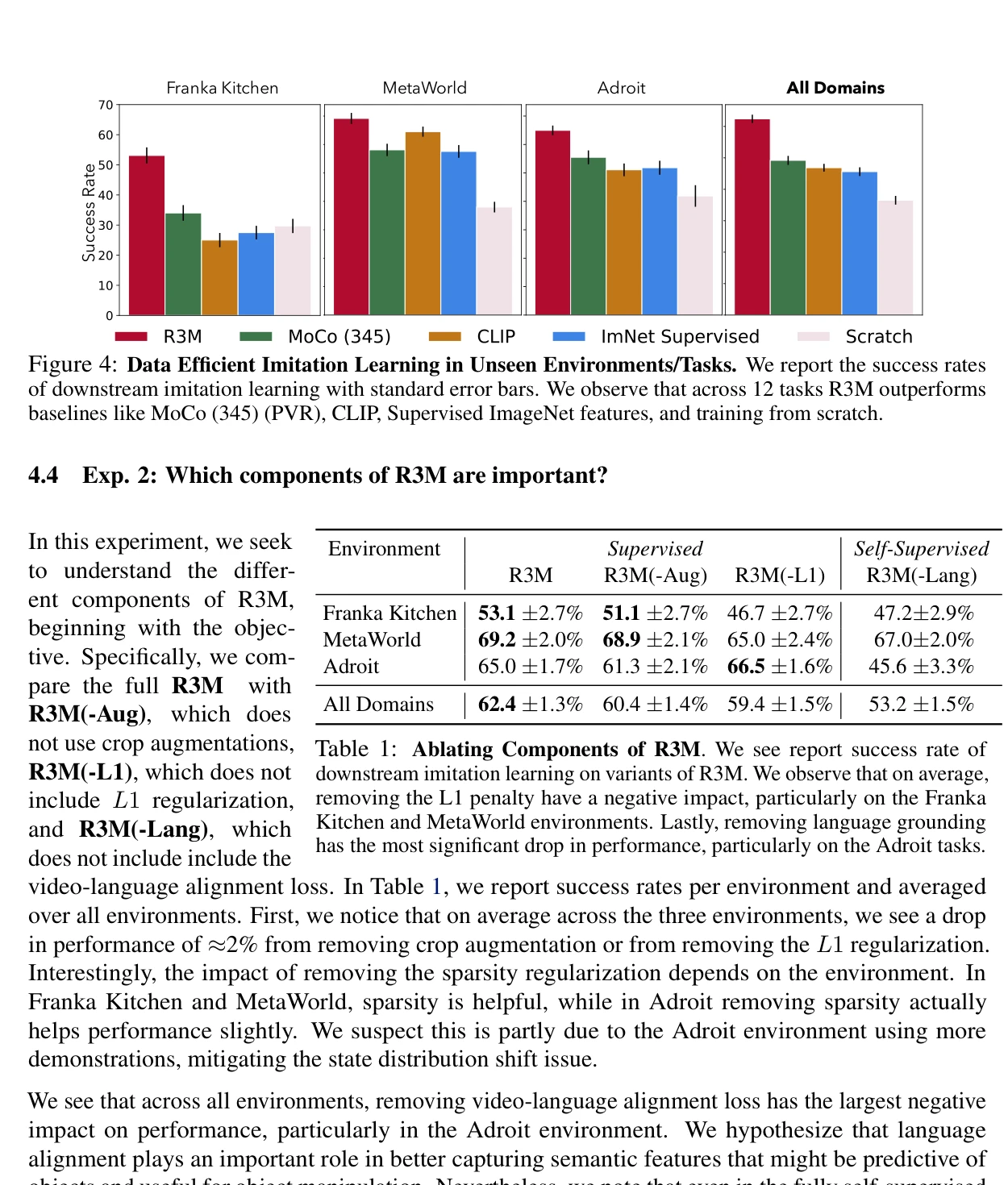
Figure 4: Data Efficient Imitation Learning in Unseen Environments/Tasks. We report the success rates
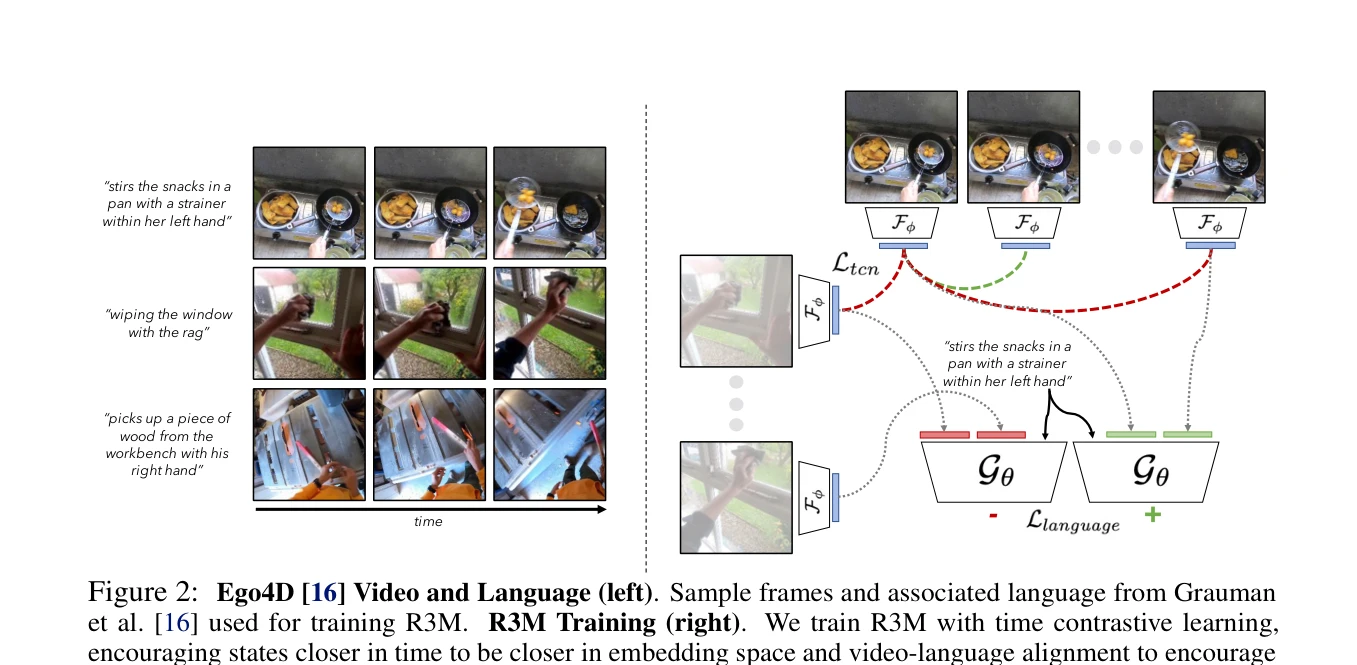
Figure 2: Ego4D [16] Video and Language (left). Sample frames and associated language from Grauman
총평: R3M은 인간 비디오 pre-training을 통해 로봇 조작의 data-efficient 학습을 달성한 중요한 실증 연구로, 실제로 다운로드 가능한 artifact를 제공함으로써 로봇 학습 커뮤니티의 standard tool 역할 가능성이 높다. 다만 실제 로봇 검증의 확장성과 표현 해석가능성 개선이 향후 과제이다.