How
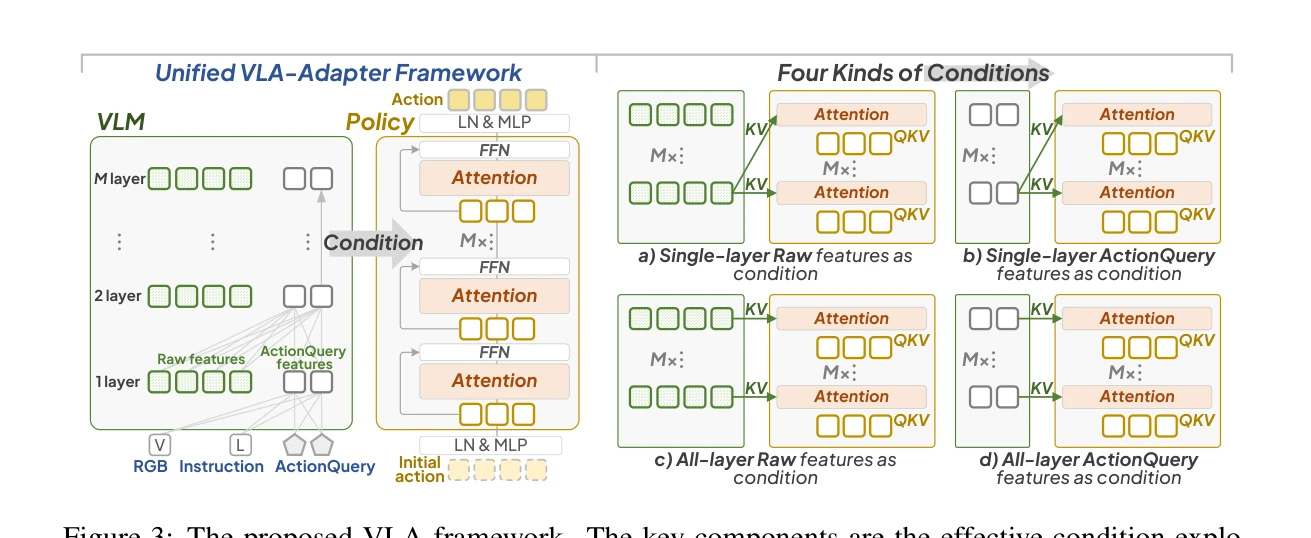
Figure 3: The proposed VLA framework. The key components are the effective condition explo-
- Prismatic-VLM 아키텍처 기반 VLM 구축 (DINOv2, SigLIP 시각 특성 추출)
- 다양한 조건 비교 실험: (1) 단일 계층 Raw features, (2) 단일 계층 ActionQuery features, (3) 전체 계층 Raw features, (4) 전체 계층 ActionQuery features
- Bridge Attention 메커니즘 설계로 조건 정보를 행동 공간에 효율적으로 주입
- Policy 네트워크가 최적 조건을 자동으로 선택하도록 학습하는 구조
- 0.5B Qwen2.5 백본으로 기본 설정, 7B LLaMA2 및 OpenVLA-7B와의 비교 실험 수행