저자: Konstantinos Bousmalis, Giulia Vezzani, Dushyant Rao, Coline Devin, Alex X. Lee, Maria Bauza, Todor Davchev, Yuxiang Zhou, Agrim Gupta, Akhil Raju, Antoine Laurens, Claudio Fantacci, Valentin Dalibard, Martina Zambelli, Murilo Martins, Rugile Pevceviciute, Michiel Blokzijl, Misha Denil, Nathan Batchelor, Thomas Lampe, Emilio Parisotto, Konrad Żołna, Scott Reed, Sergio Gómez Colmenarejo, Jon Scholz, Abbas Abdolmaleki, Oliver Groth, Jean-Baptiste Regli, Oleg Sushkov, Tom Rothörl, José Enrique Chen, Yusuf Aytar, Dave Barker, Joy Ortiz, Martin Riedmiller, Jost Tobias Springenberg, Raia Hadsell, Francesco Nori, Nicolas Heess | 날짜: 2023-06-20 | URL: https://arxiv.org/abs/2306.11706 📄 PDF
Essence
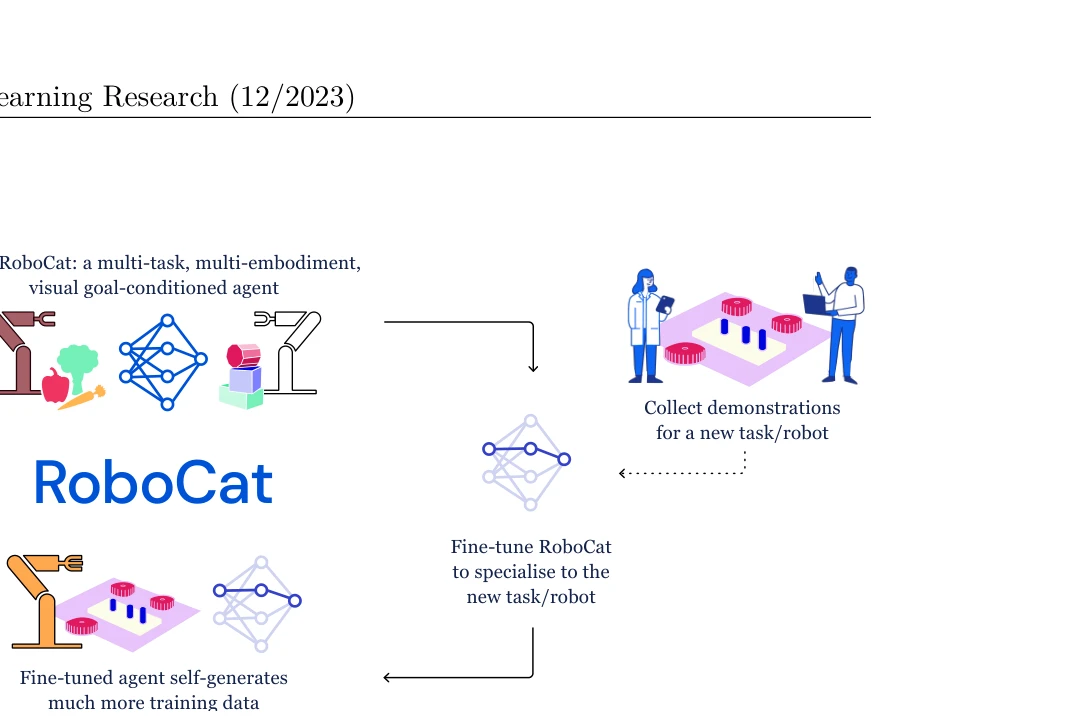
Figure 1: The self-improvement process. RoboCat is a multi-task, multi-embodiment visual goal-conditioned
RoboCat는 서로 다른 로봇과 작업 경험을 활용하여 다중 embodiment과 다중 작업을 처리할 수 있는 시각 기반 goal-conditioned decision transformer 기반의 자가 개선 로봇 조작 에이전트이다. 100-1000개의 예제만으로 새로운 작업과 로봇에 적응하며, 자체 생성 데이터를 이용한 반복적 개선이 가능하다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: RoboCat는 foundation model 패러다임을 로봇 조작에 성공적으로 적용하여 이질적 embodiment 처리, 효율적 적응, 자가 개선을 동시에 달성한 획기적 연구이다. 광범위한 실험 검증과 명확한 presentation이 강점이나, 복잡도 증가와 장기 scaling에 대한 분석이 향후 과제이다.