Essence
Figure 1: We introduce CrossFormer, a transformer-based policy trained on 900K trajectories of diverse,
CrossFormer는 20개의 서로 다른 로봇 embodiment에서 900K 궤적으로 학습된 단일 transformer 기반 정책으로, 관찰 및 행동 공간의 수동 정렬 없이 조작, 네비게이션, 보행, 항공 로봇을 모두 제어할 수 있다.
저자: Ria Doshi, Homer Walke, Oier Mees, Sudeep Dasari, Sergey Levine | 날짜: 2024-08-21 | URL: https://arxiv.org/abs/2408.11812 📄 PDF
Figure 1: We introduce CrossFormer, a transformer-based policy trained on 900K trajectories of diverse,
CrossFormer는 20개의 서로 다른 로봇 embodiment에서 900K 궤적으로 학습된 단일 transformer 기반 정책으로, 관찰 및 행동 공간의 수동 정렬 없이 조작, 네비게이션, 보행, 항공 로봇을 모두 제어할 수 있다.
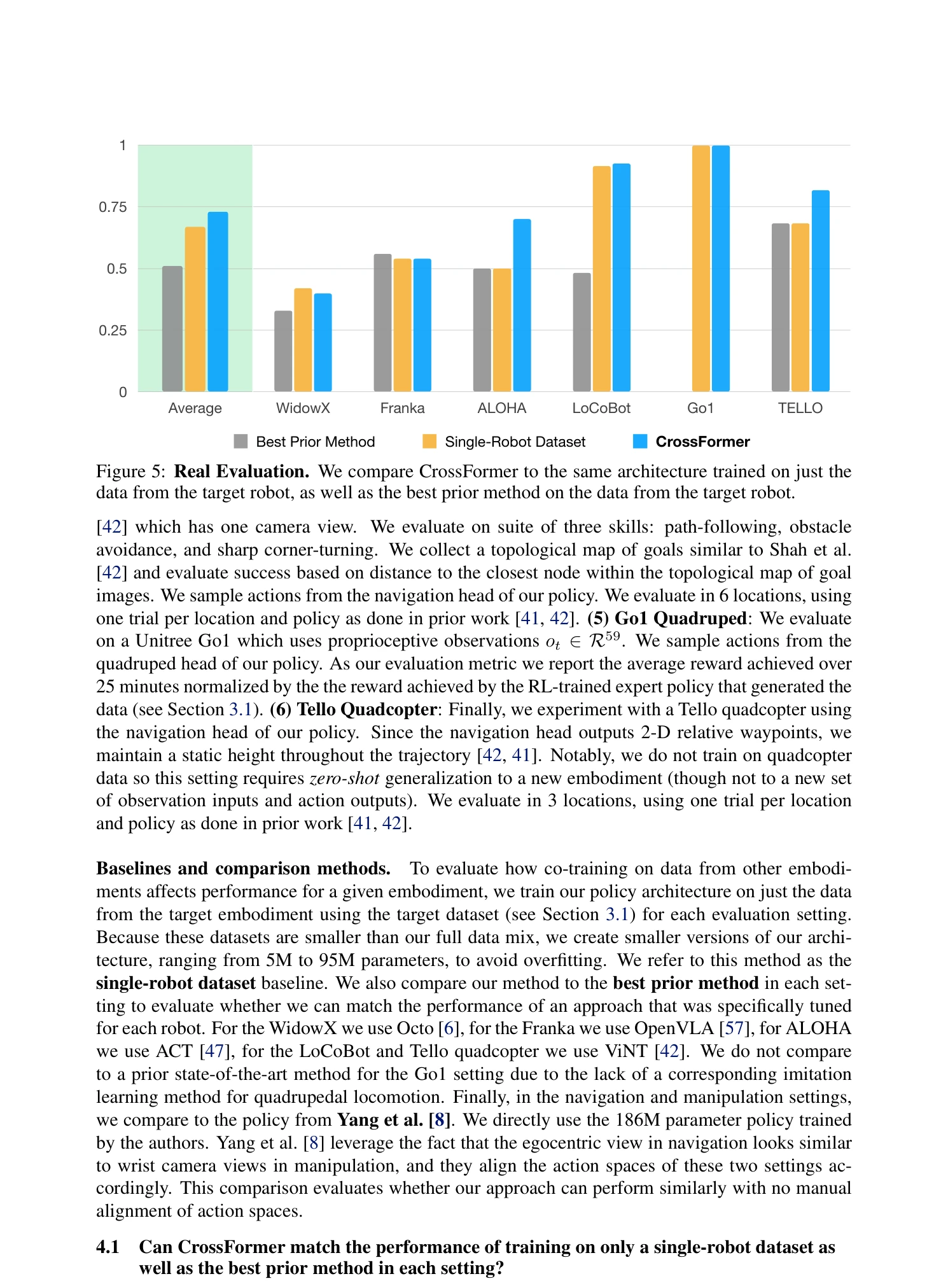
Figure 5: Real Evaluation. We compare CrossFormer to the same architecture trained on just the
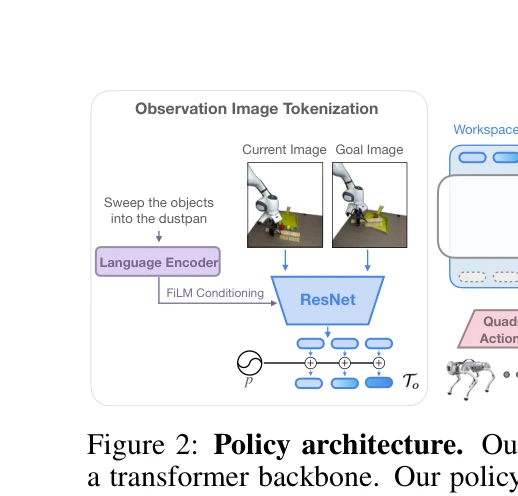
Figure 2: Policy architecture. Our architecture enables cross-embodied policy learning through
총평: CrossFormer는 cross-embodied 로봇 학습에서 획기적인 진전을 이루었으며, 실용적인 문제(센서/액추에이터 이질성)를 우아하게 해결하고 광범위한 실제 실험으로 검증된 강력한 작업이다.