Essence
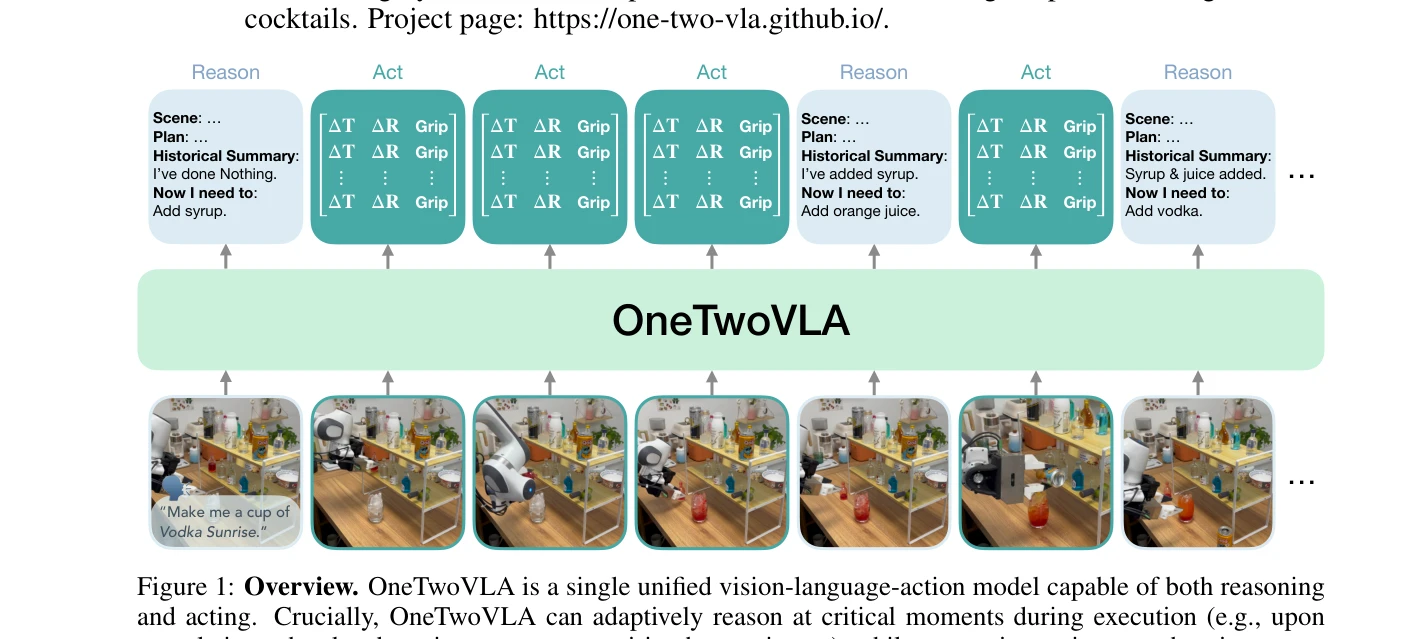
Figure 1: Overview. OneTwoVLA is a single unified vision-language-action model capable of both reasoning
OneTwoVLA는 단일 통합 vision-language-action 모델로서 reasoning과 acting을 모두 수행하며, 작업 실행 중 critical moment에서는 explicit reasoning을, 그 외에는 reasoning 기반 action generation으로 adaptively switch한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: OneTwoVLA는 dual-system의 근본적 문제를 unified model로 해결하면서 adaptive reasoning-acting mechanism을 통해 효율성과 성능의 balance를 달성한 혁신적 접근법이다. Embodied vision-language co-training strategy와 함께 long-horizon robot control의 새로운 표준을 제시하며, ICLR 2026 발표의 significance를 충분히 입증한다.