저자: Shuai Yang, Hao Li, Bin Wang, Yilun Chen, Yang Tian, Tai Wang, Hanqing Wang, Feng Zhao, Yiyi Liao, Jiangmiao Pang | 날짜: 2025-07-23 | URL: https://arxiv.org/abs/2507.17520 📄 PDF
Essence
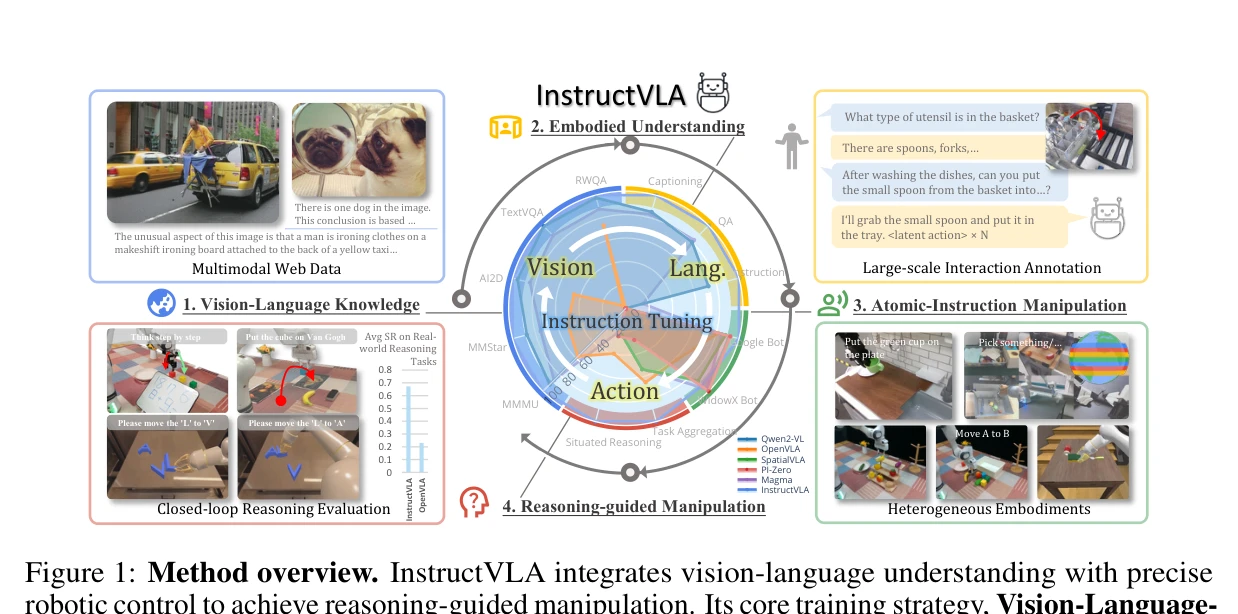
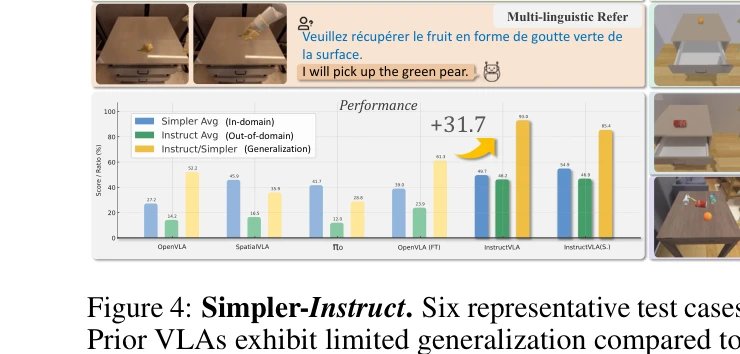
Figure 1: Method overview. InstructVLA integrates vision-language understanding with precise
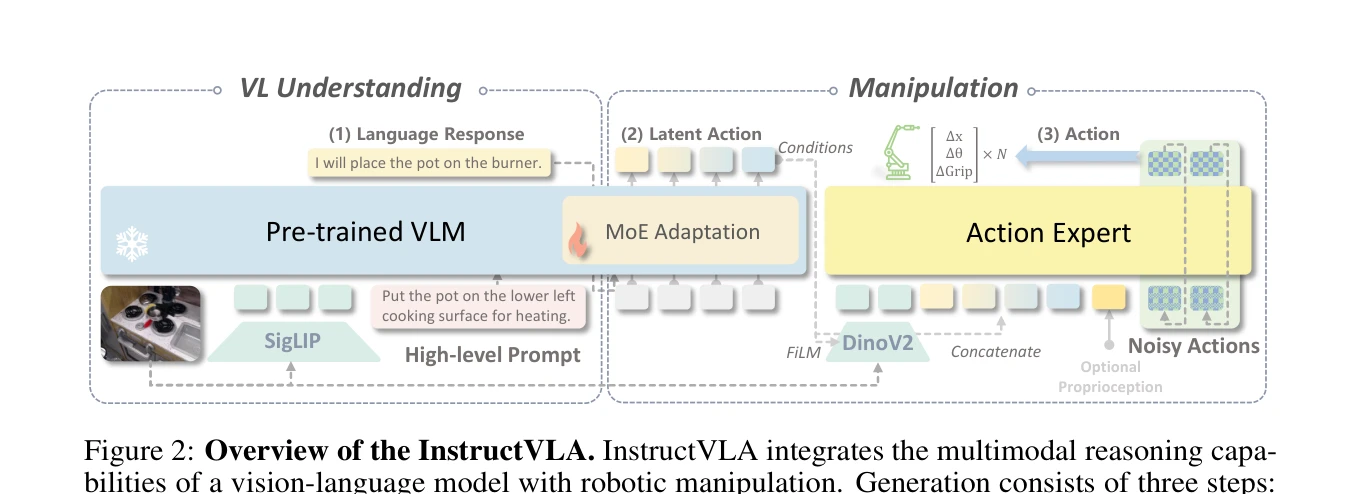
InstructVLA는 Vision-Language Model의 추론 능력을 보존하면서 로봇 조작 성능을 달성하는 end-to-end VLA 모델이며, Vision-Language-Action Instruction Tuning (VLA-IT) 패러다임을 통해 multimodal reasoning과 action generation을 동시에 최적화한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: InstructVLA는 VLA 분야에서 multimodal reasoning과 precise action generation의 균형을 이루는 중요한 진전을 보여주며, VLA-IT 패러다임과 mixture-of-experts 통합 방식은 신선한 기술적 기여를 제시한다. 다만 real-world 검증 범위와 open-world generalization에 대한 추가 평가가 필요하다.