저자: Hengtao Li, Pengxiang Ding, Runze Suo, Yihao Wang, Zirui Ge, Dongyuan Zang, Kexian Yu, Mingyang Sun, Hongyin Zhang, Donglin Wang, Weihua Su | 날짜: 2025-10-01 | URL: https://arxiv.org/abs/2510.00406 📄 PDF
Essence
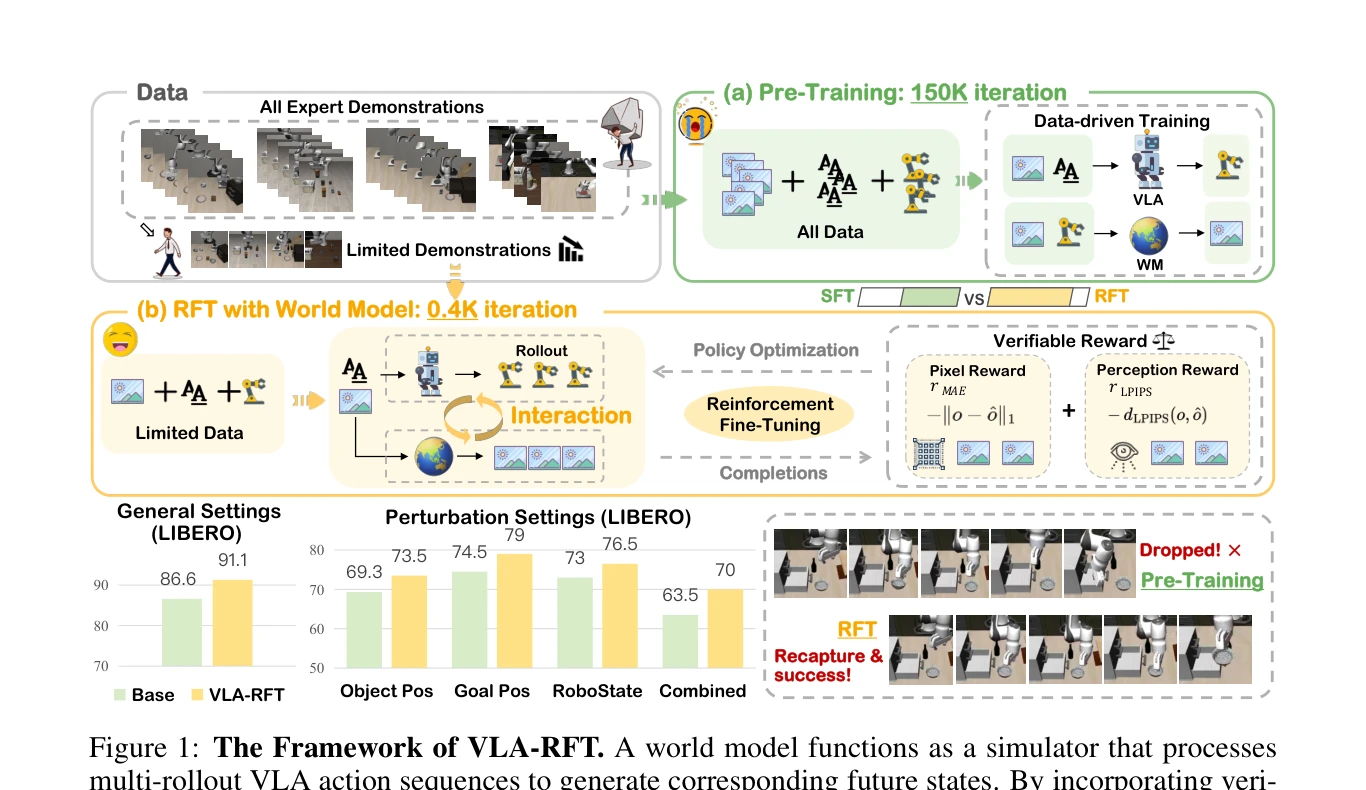
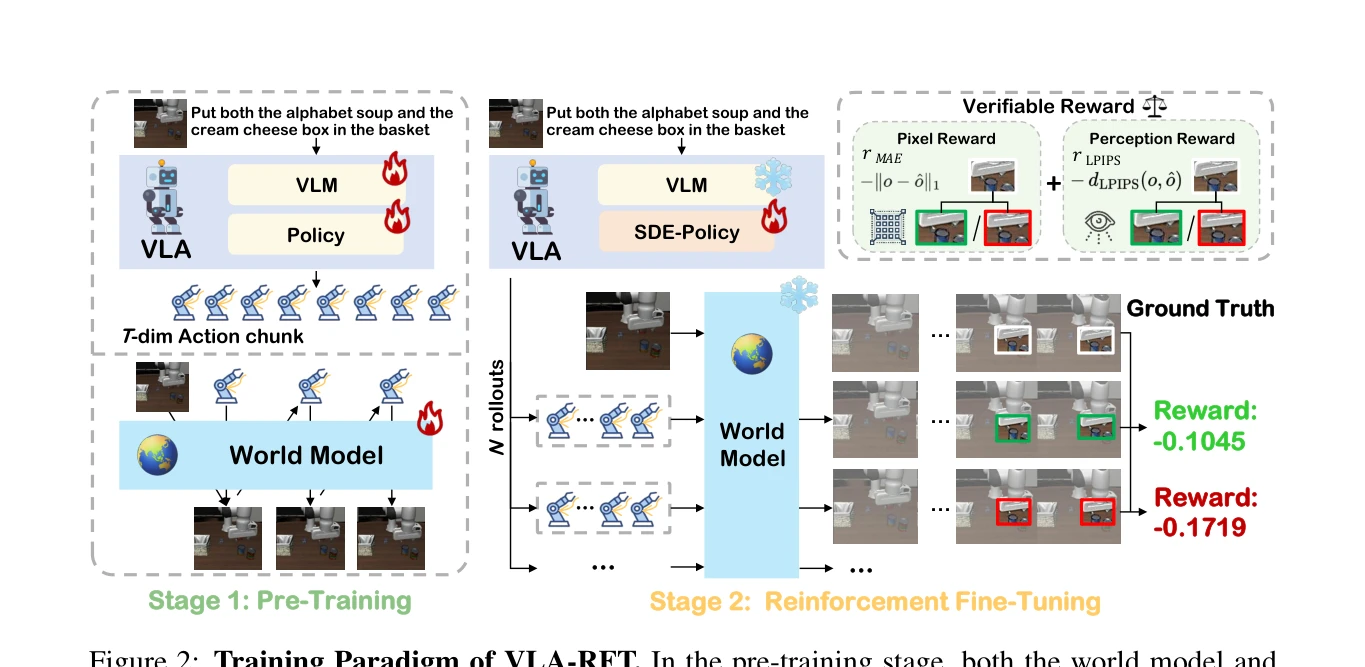
Figure 1: The Framework of VLA-RFT. A world model functions as a simulator that processes
VLA-RFT는 데이터 기반 world model을 시뮬레이터로 활용하여 vision-language-action 모델을 reinforcement learning으로 효율적으로 fine-tuning하는 프레임워크이다. 검증된 reward를 기반으로 GRPO 최적화를 수행하여 400 단계 이하의 fine-tuning으로 strong supervised baseline을 초과하는 성능을 달성한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: VLA-RFT는 world model 기반 reinforcement fine-tuning을 통해 효율성, 성능, robustness를 동시에 달성하는 실용적이고 창의적인 접근법을 제시한다. 극도로 제한된 fine-tuning 단계로 strong baseline을 초과하고 perturbed 환경에서 일관된 성능을 유지하는 점에서 높은 가치가 있으나, 실제 로봇 환경에서의 검증과 장기 horizon task에 대한 분석이 필요하다.