Essence

Fig. 1.
UniAff는 도구 사용과 관절형 객체 조작을 통합하는 MLLM 기반 프레임워크로, 3D motion constraints와 affordances의 통일된 표현을 제시한다.
저자: Qiaojun Yu, Siyuan Huang, Xibin Yuan, Zhengkai Jiang, Ce Hao, Xin Li, Haonan Chang, Junbo Wang, Liu Liu, Hongsheng Li, Peng Gao, Cewu Lu | 날짜: 2024-09-30 | URL: https://arxiv.org/abs/2409.20551 📄 PDF
Fig. 1.
UniAff는 도구 사용과 관절형 객체 조작을 통합하는 MLLM 기반 프레임워크로, 3D motion constraints와 affordances의 통일된 표현을 제시한다.
Fig. 1.
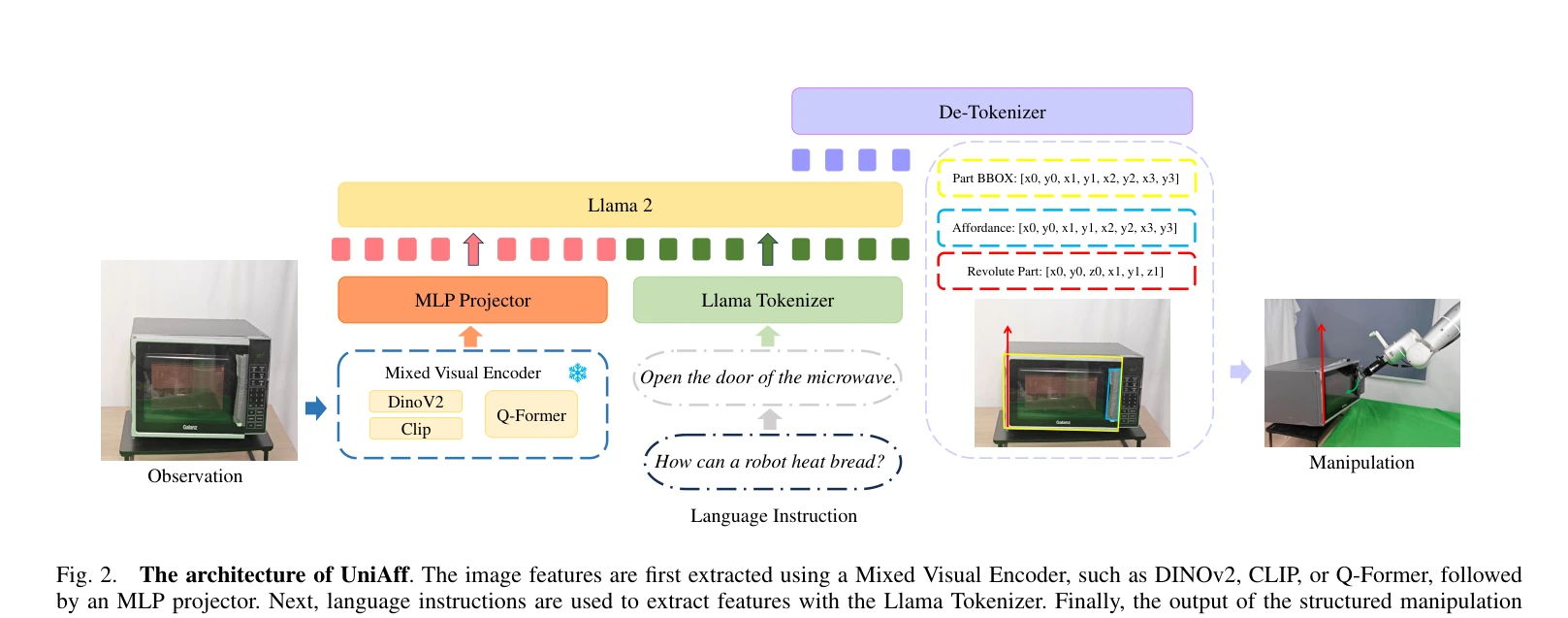
Fig. 2.
총평: UniAff는 도구와 관절형 객체 조작을 최초로 통합하는 MLLM 기반 프레임워크로, 구조화된 부품 표현과 대규모 synthetic dataset을 통해 로봇 조작의 일반화 능력을 크게 향상시킨 의미 있는 연구 성과이다.