Essence
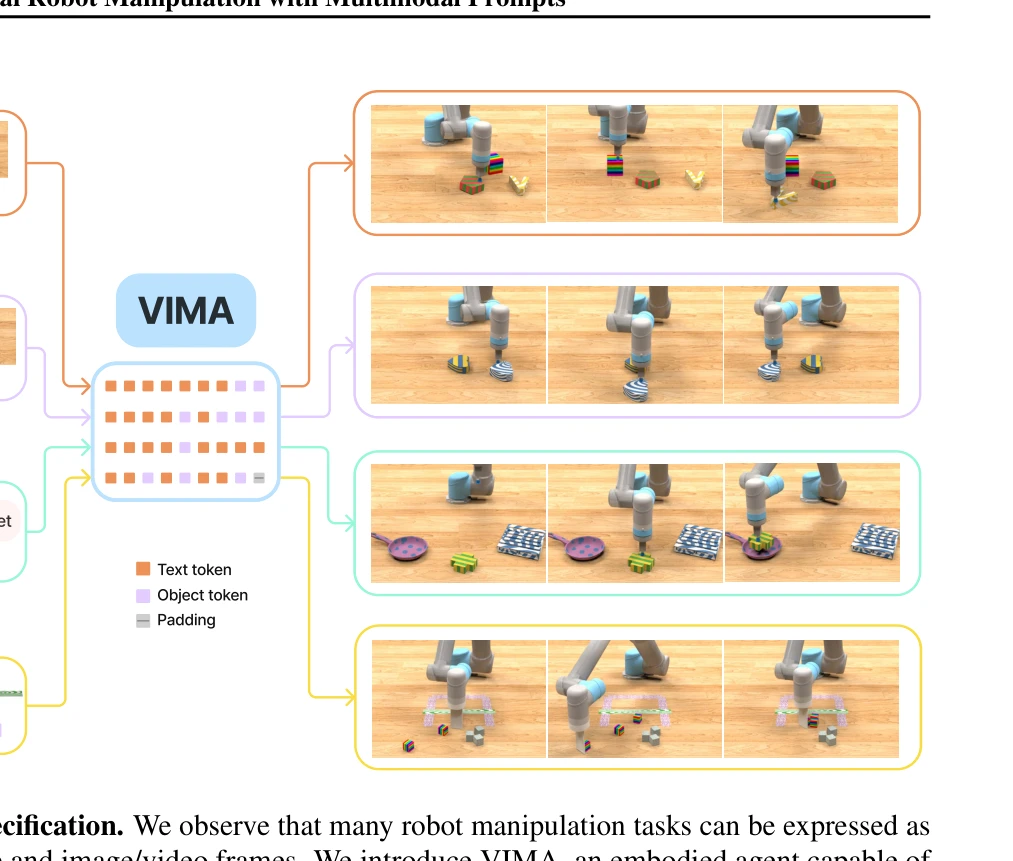
Figure 1: Multimodal prompts for task specification. We observe that many robot manipulation tasks can be expressed as
멀티모달 프롬프트(텍스트와 이미지 혼합)를 사용하여 다양한 로봇 조작 작업을 통일된 시퀀스 모델링 문제로 표현하고, 이를 처리할 수 있는 transformer 기반 로봇 에이전트 VIMA를 제시한다.
저자: Yunfan Jiang, Agrim Gupta, Zichen Zhang, Guanzhi Wang, Yongqiang Dou, Yanjun Chen, Li Fei-Fei, Anima Anandkumar, Yuke Zhu, Linxi Fan | 날짜: 2022-10-06 | URL: https://arxiv.org/abs/2210.03094 📄 PDF
Figure 1: Multimodal prompts for task specification. We observe that many robot manipulation tasks can be expressed as
멀티모달 프롬프트(텍스트와 이미지 혼합)를 사용하여 다양한 로봇 조작 작업을 통일된 시퀀스 모델링 문제로 표현하고, 이를 처리할 수 있는 transformer 기반 로봇 에이전트 VIMA를 제시한다.
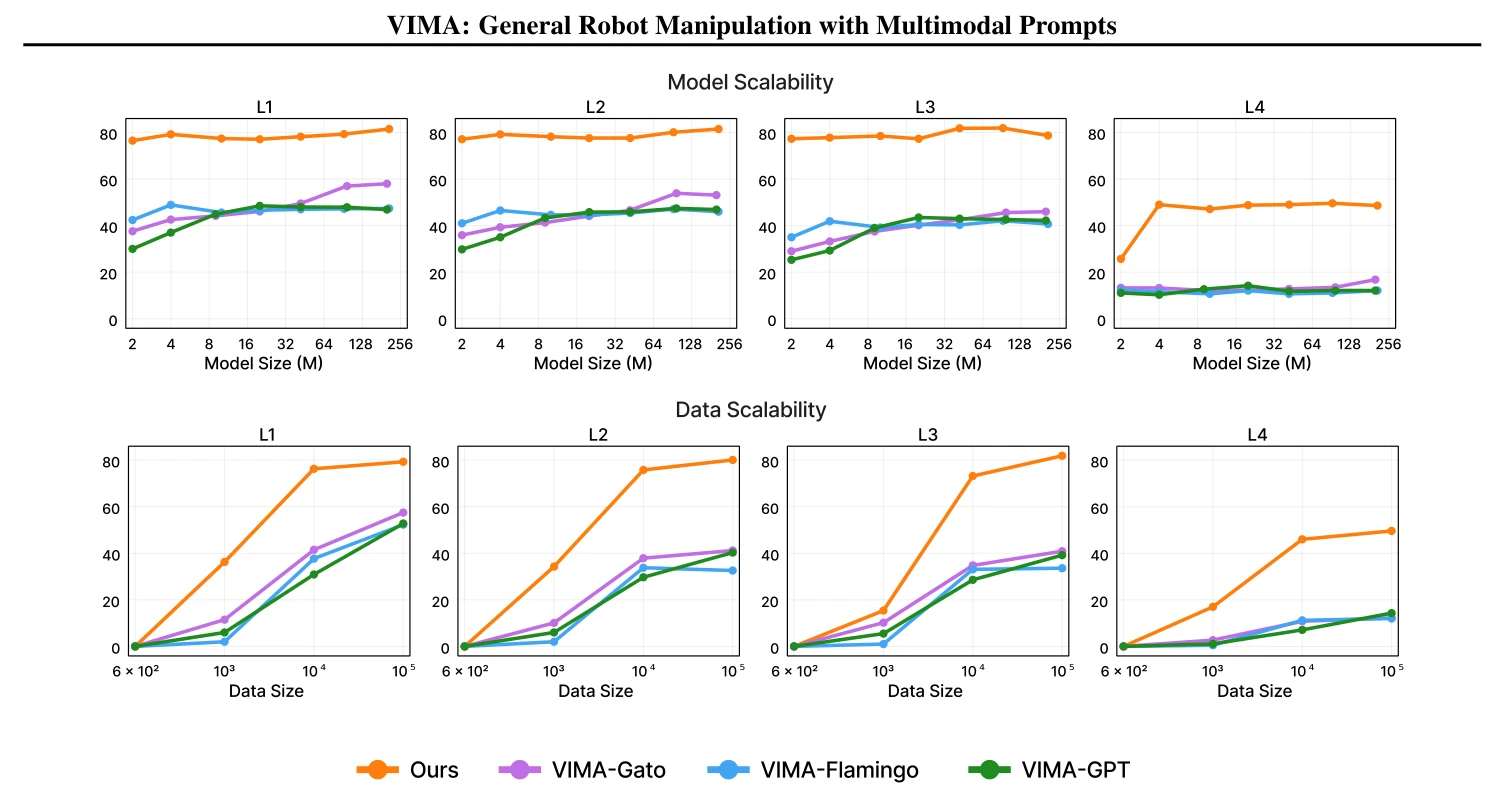
Figure 4: Scaling model and data. Top: We compare performance of different methods with model sizes ranging from 2M
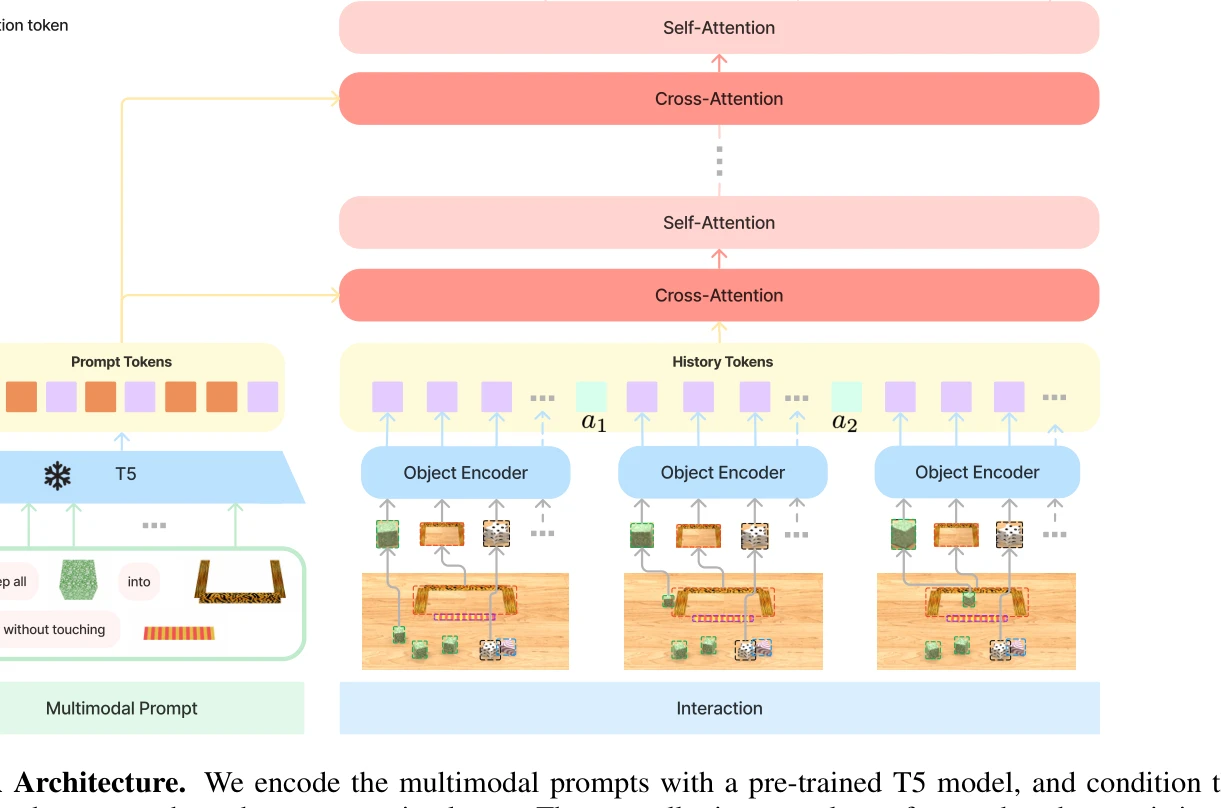
Figure 3: VIMA Architecture. We encode the multimodal prompts with a pre-trained T5 model, and condition the
총평: 멀티모달 프롬프트를 통해 다양한 로봇 조작 작업을 통일된 프레임워크로 표현한 획기적 접근법으로, 체계적인 벤치마크와 함께 높은 일반화 성능을 달성하였다. 로봇 학습의 task specification 문제에 대한 창의적 해결책을 제시하며 개방형 재현 자료를 통해 커뮤니티 기여도 높다.