Essence
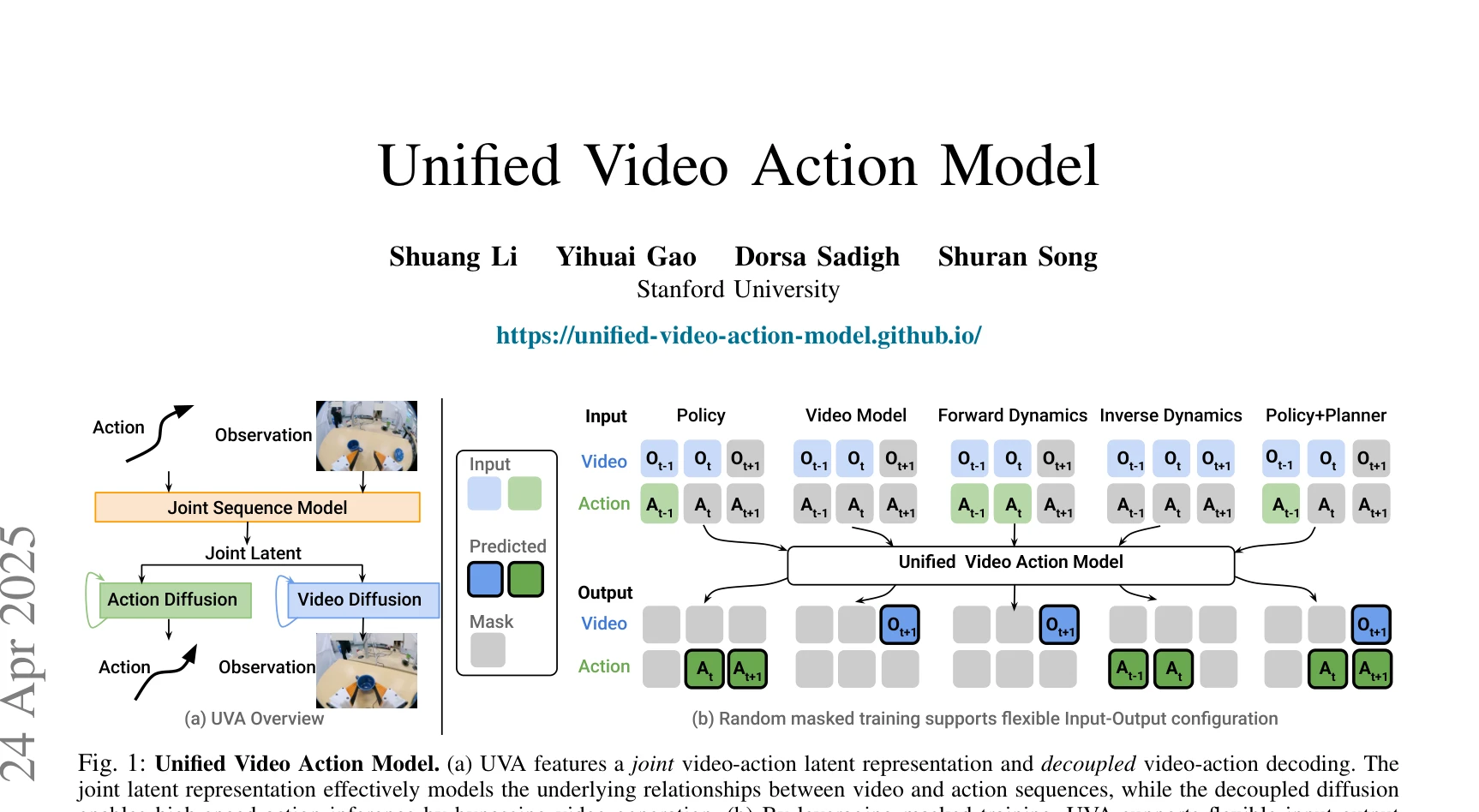
Fig. 1: Unified Video Action Model. (a) UVA features a joint video-action latent representation and decoupled video-acti
UVA는 비디오 생성과 액션 예측을 통합적으로 학습하는 모델로, 공유된 잠재 표현과 분리된 확산 헤드를 통해 높은 정확도와 빠른 추론 속도를 동시에 달성한다.
저자: Shuang Li, Yihuai Gao, Dorsa Sadigh, Shuran Song | 날짜: 2025-02-28 | URL: https://arxiv.org/abs/2503.00200 📄 PDF
Fig. 1: Unified Video Action Model. (a) UVA features a joint video-action latent representation and decoupled video-acti
UVA는 비디오 생성과 액션 예측을 통합적으로 학습하는 모델로, 공유된 잠재 표현과 분리된 확산 헤드를 통해 높은 정확도와 빠른 추론 속도를 동시에 달성한다.
Fig. 1: Unified Video Action Model. (a) UVA features a joint video-action latent representation and decoupled video-acti
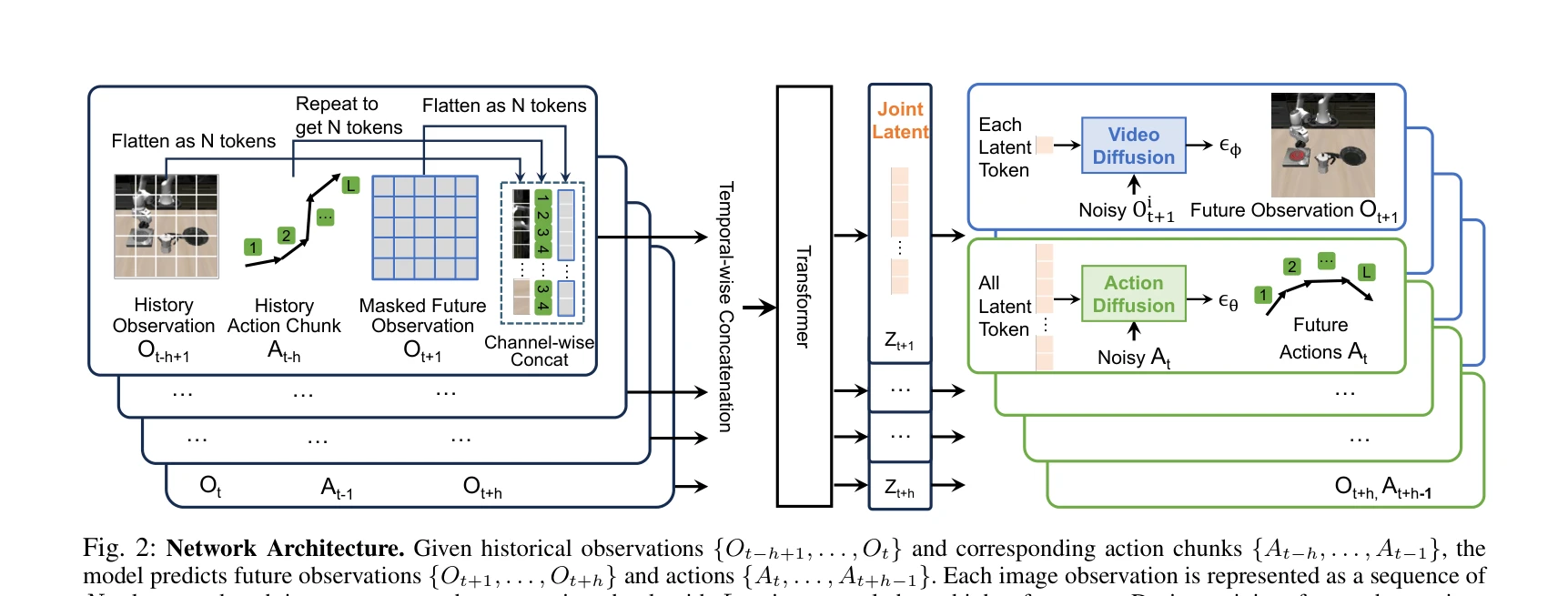
Fig. 2: Network Architecture. Given historical observations {Ot−h+1, . . . , Ot} and corresponding action chunks {At−h,
총평: UVA는 비디오와 액션 학습의 오랜 트레이드오프를 통합 잠재 표현과 분리된 디코딩으로 효과적으로 해결하며, 마스크 훈련을 통한 다목적 활용으로 로봇 학습 프레임워크의 실용성을 크게 향상시킨다.