Essence

Fig. 1: Schematic representation of VLA-0. VLA-0 con-
VLA-0는 Vision-Language Model의 구조 변경 없이 액션을 직접 텍스트로 표현하여 로봇 조작을 위한 최첨단 Vision-Language-Action 모델을 구축한다. 이 단순한 설계가 기존의 복잡한 방법들보다 우수한 성능을 달성한다.
저자: Ankit Goyal, Hugo Hadfield, Xuning Yang, Valts Blukis, Fabio Ramos | 날짜: 2025-10-15 | URL: https://arxiv.org/abs/2510.13054 📄 PDF
Fig. 1: Schematic representation of VLA-0. VLA-0 con-
VLA-0는 Vision-Language Model의 구조 변경 없이 액션을 직접 텍스트로 표현하여 로봇 조작을 위한 최첨단 Vision-Language-Action 모델을 구축한다. 이 단순한 설계가 기존의 복잡한 방법들보다 우수한 성능을 달성한다.
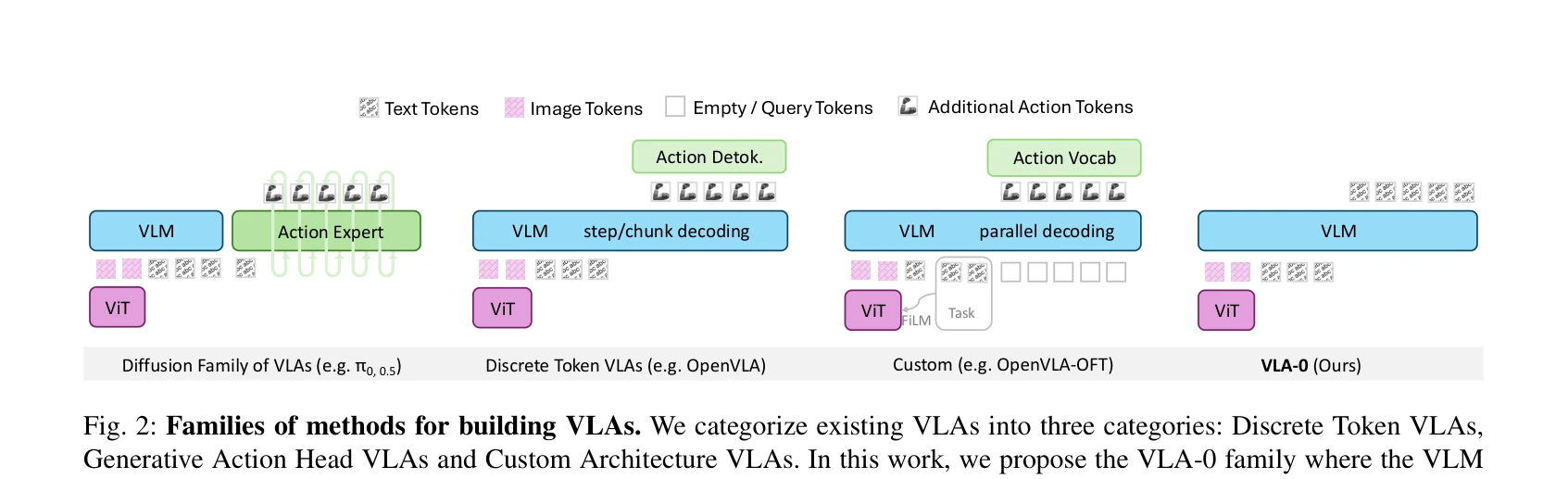
Fig. 2: Families of methods for building VLAs. We categorize existing VLAs into three categories: Discrete Token VLAs,
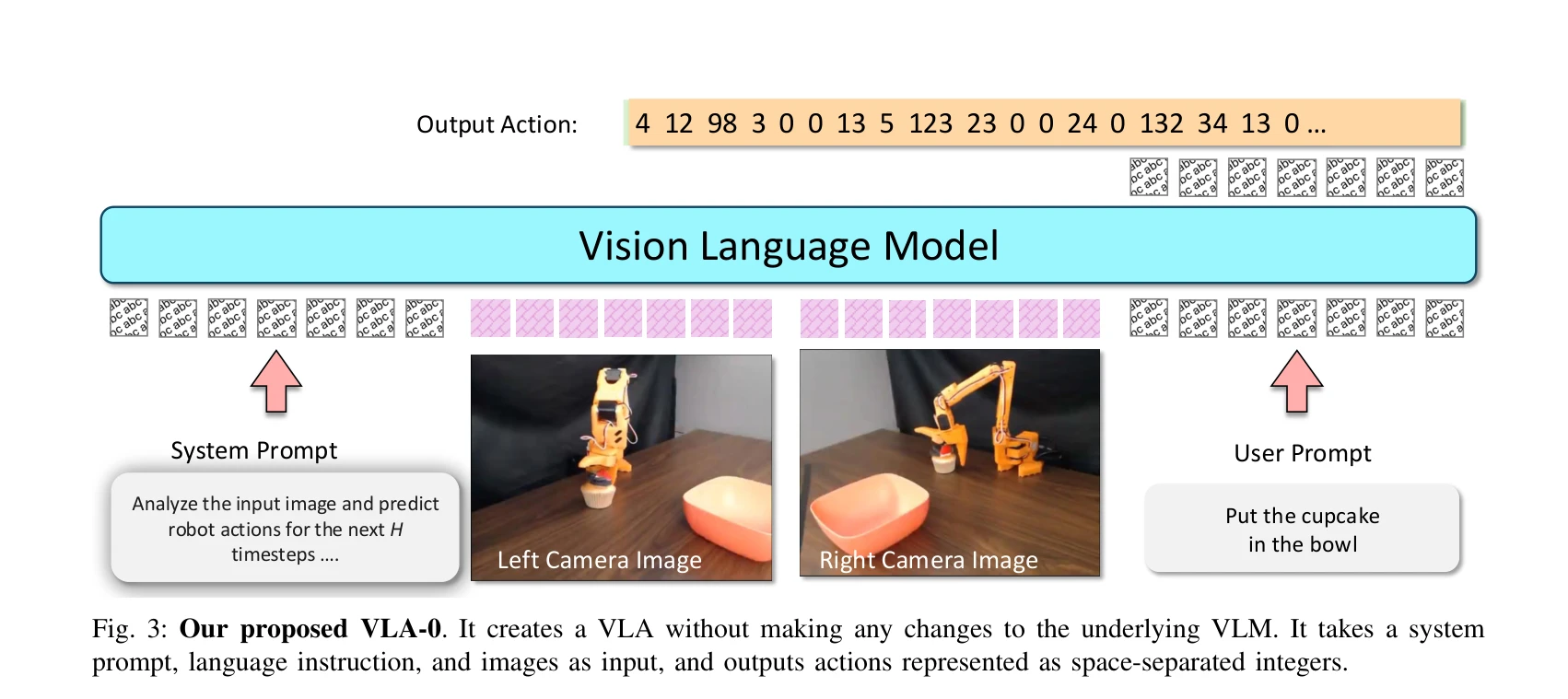
Fig. 3: Our proposed VLA-0. It creates a VLA without making any changes to the underlying VLM. It takes a system
총평: VLA-0는 예상을 뒤엎고 가장 단순한 설계가 최첨단 성능을 달성 가능함을 입증하여 VLA 분야에 중요한 통찰을 제공한다. 코드와 모델 공개를 통한 재현성과 실용성이 높으며, VLM 기반 로봇 제어 연구에 새로운 방향을 제시한다.