저자: Dapeng Zhang, Jing Sun, Chenghui Hu, Xiaoyan Wu, Zhenlong Yuan, Rui Zhou, Fei Shen, Qingguo Zhou | 날짜: 2025-09-23 | URL: https://arxiv.org/abs/2509.19012 📄 PDF
Essence
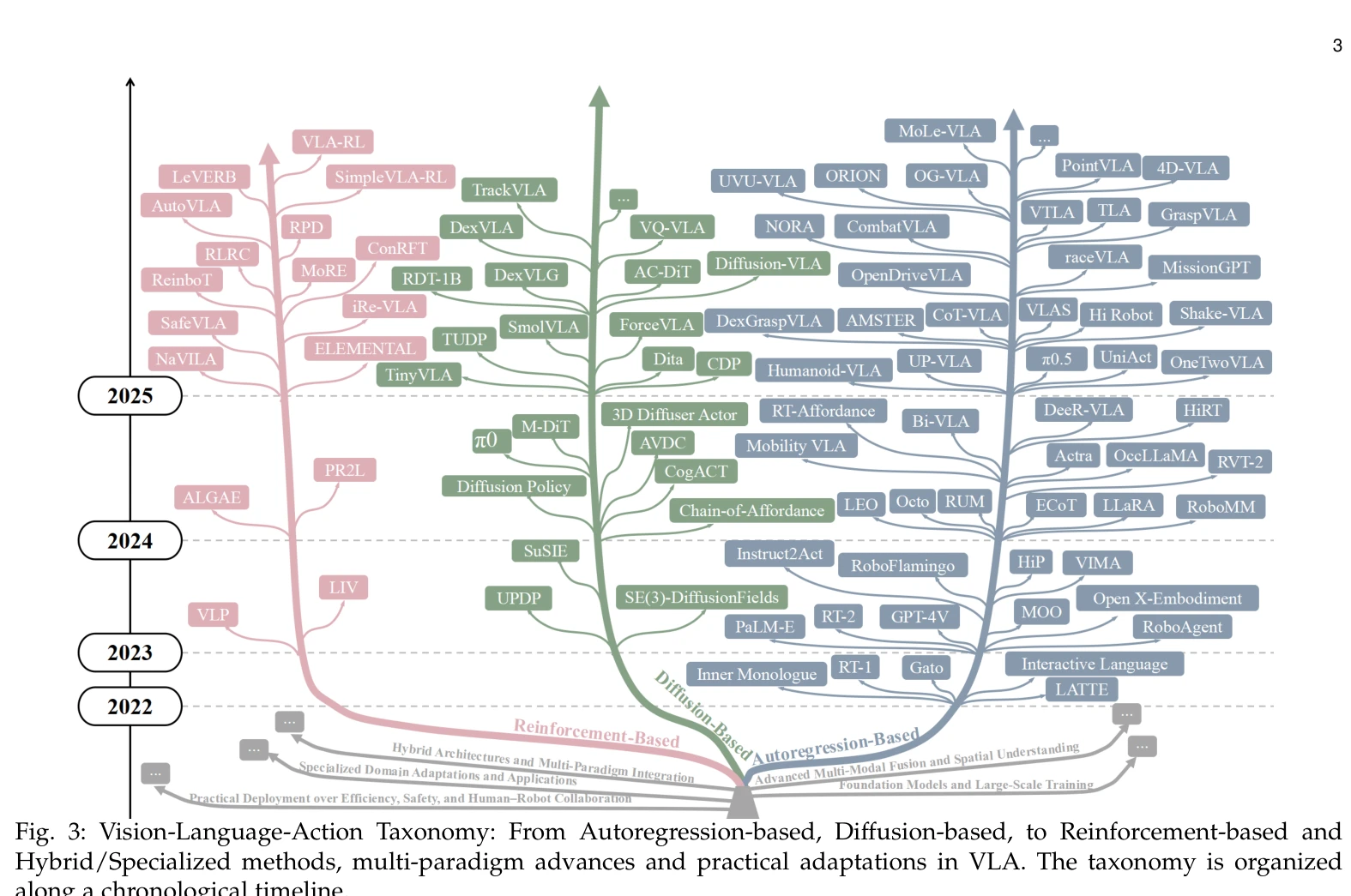
Fig. 3: Vision-Language-Action Taxonomy: From Autoregression-based, Diffusion-based, to Reinforcement-based and
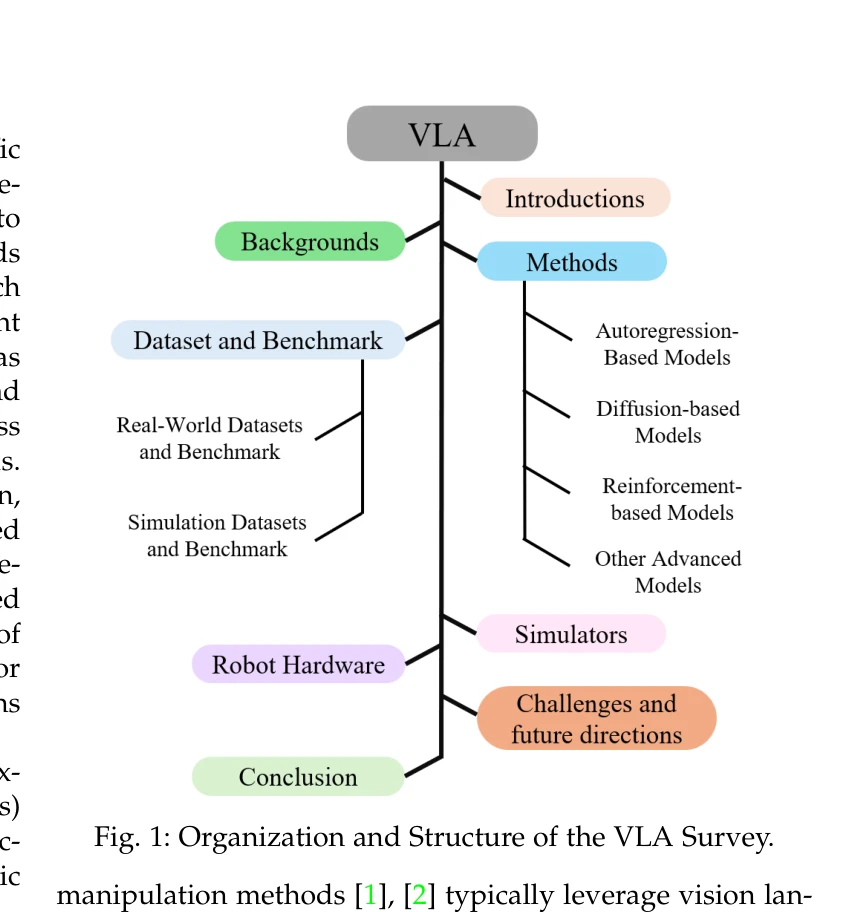
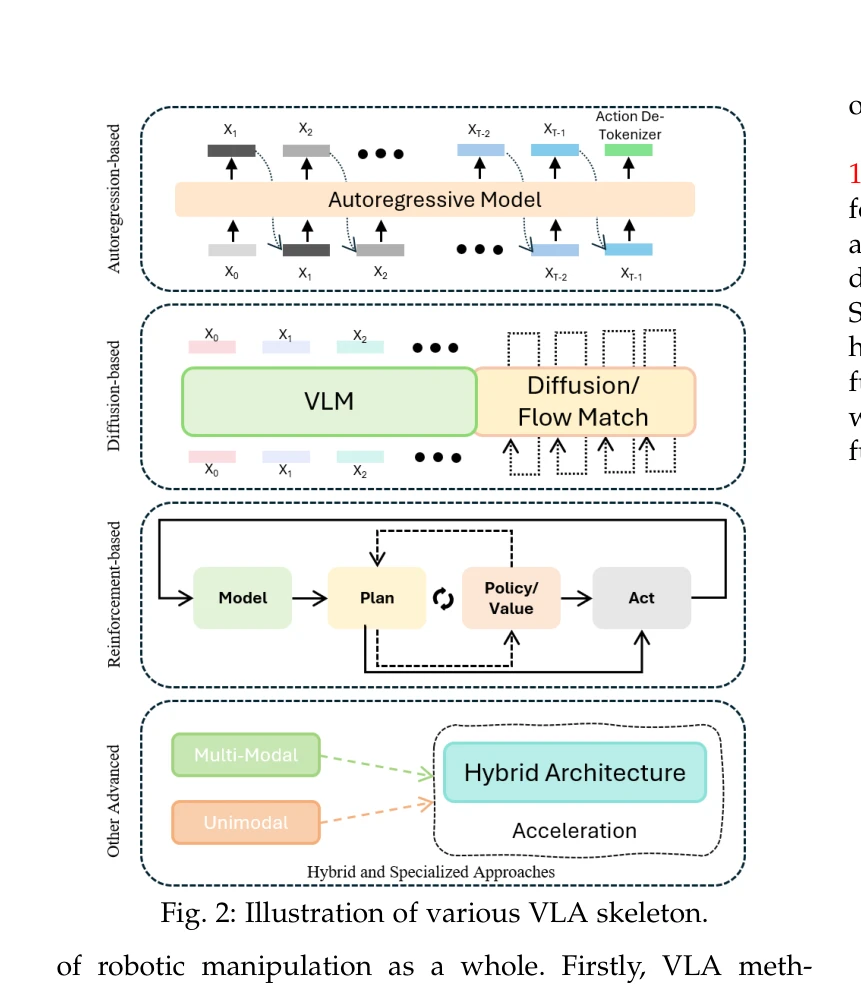
본 논문은 Vision Language Action (VLA) 모델을 체계적으로 분류하고 분석하는 포괄적 서베이로, autoregression-based, diffusion-based, reinforcement-based, hybrid, specialized methods로 VLA 접근법을 분류하여 300개 이상의 최근 연구를 종합한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 본 서베이는 VLA 분야의 급속한 발전 속에서 처음으로 체계적인 분류체계를 제시하고 300개 이상의 연구를 종합하여 현황 맵핑을 제공함으로써, VLA 연구자와 로봇공학자들에게 높은 학술적 가치를 제공한다. 다만 시뮬레이션-현실 갭, 평가 메트릭 표준화, 최신 방법론 수용 측면의 개선이 향후 필요하다.