Essence

Figure 1: We present OpenVLA, a 7B-parameter open-source vision-language-action model (VLA), trained
OpenVLA는 970k개의 로봇 시연 데이터로 학습된 7B 파라미터의 오픈소스 Vision-Language-Action 모델로, 폐쇄형 모델들보다 우수한 성능을 보이면서 효율적인 미세조정과 배포를 지원한다.
저자: Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, Chelsea Finn | 날짜: 2024-06-13 | URL: https://arxiv.org/abs/2406.09246 📄 PDF
Figure 1: We present OpenVLA, a 7B-parameter open-source vision-language-action model (VLA), trained
OpenVLA는 970k개의 로봇 시연 데이터로 학습된 7B 파라미터의 오픈소스 Vision-Language-Action 모델로, 폐쇄형 모델들보다 우수한 성능을 보이면서 효율적인 미세조정과 배포를 지원한다.
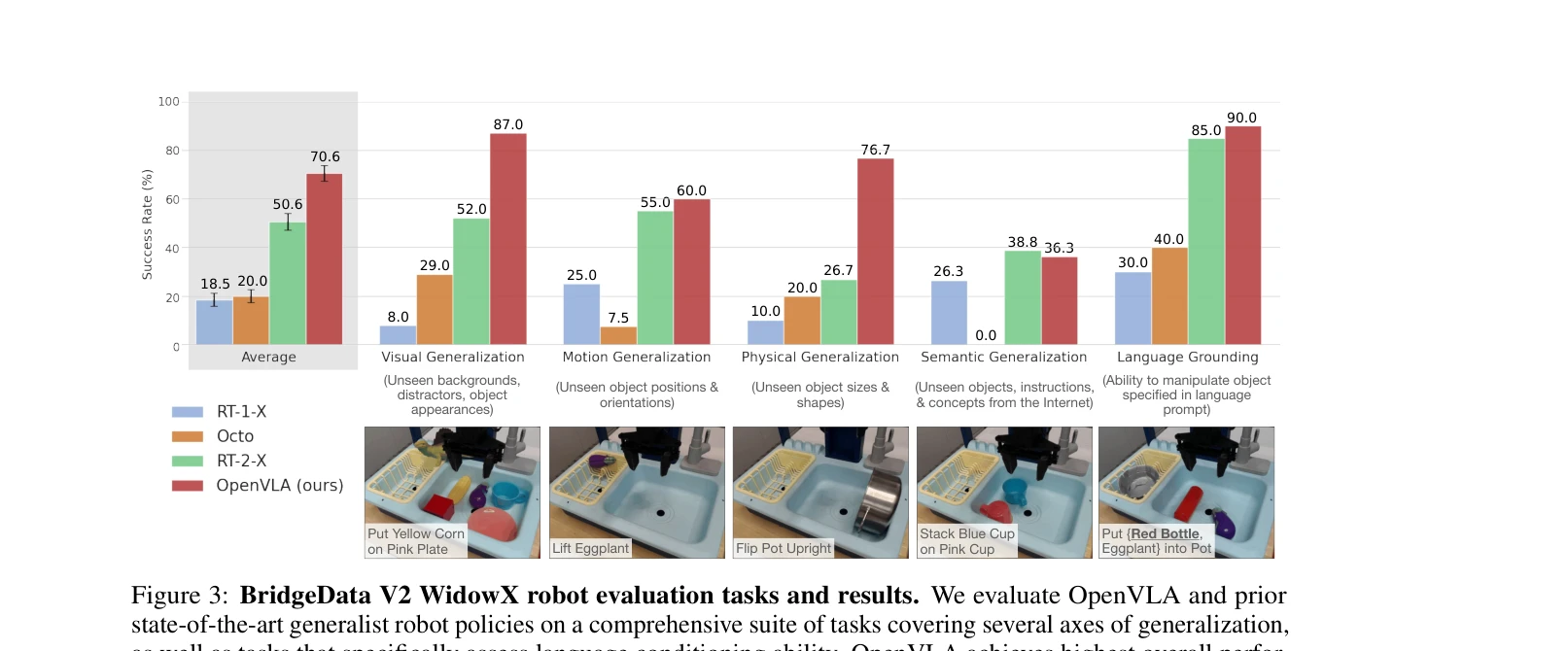
Figure 3: BridgeData V2 WidowX robot evaluation tasks and results. We evaluate OpenVLA and prior
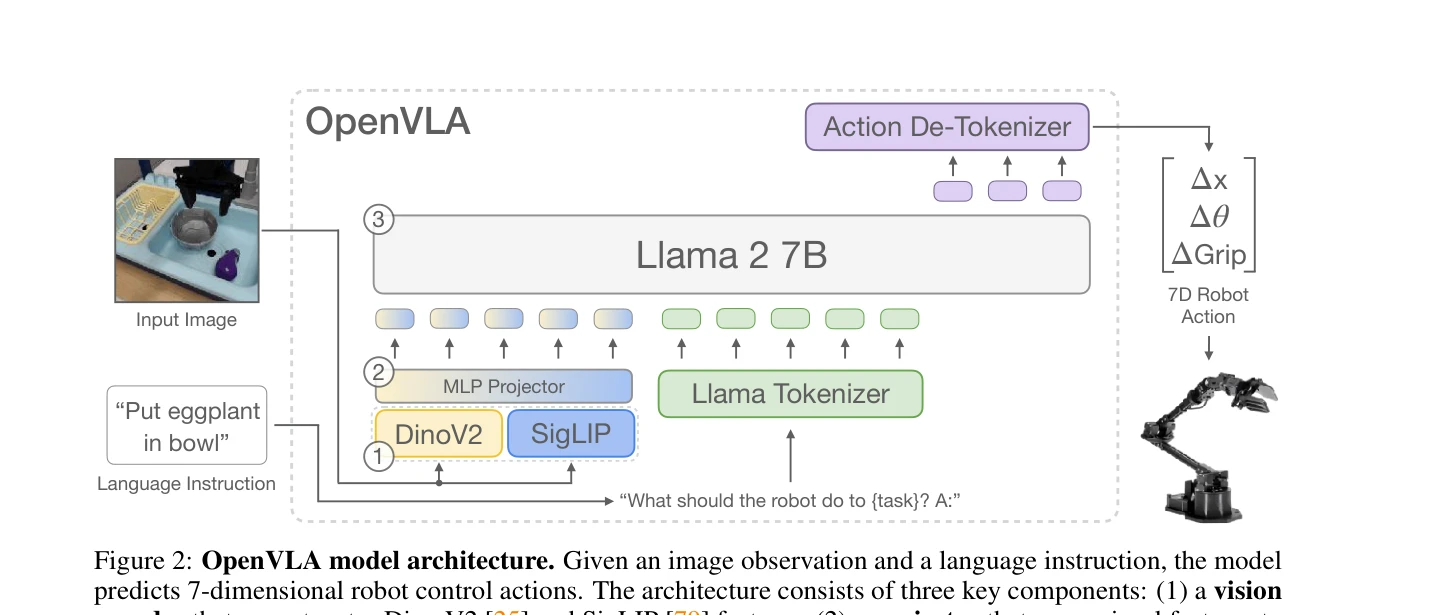
Figure 2: OpenVLA model architecture. Given an image observation and a language instruction, the model
총평: OpenVLA는 폐쇄형 대규모 VLA 모델을 능가하는 성능을 더 작은 파라미터로 달성하면서 완전한 오픈소스 공개와 효율적 미세조정 방법을 제시하여 로봇 분야의 파운데이션 모델 생태계 구축에 중요한 기여를 한다.