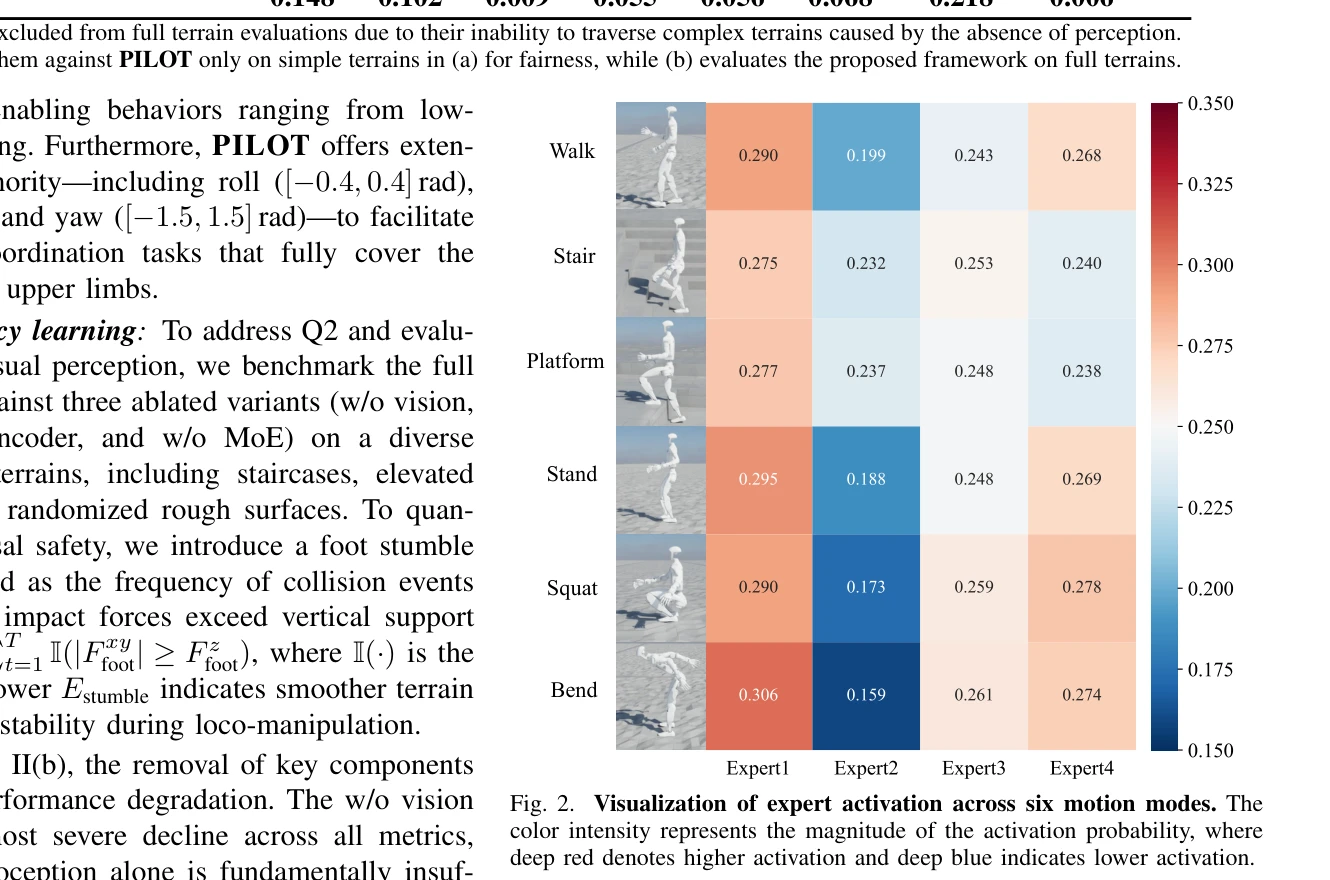
Essence
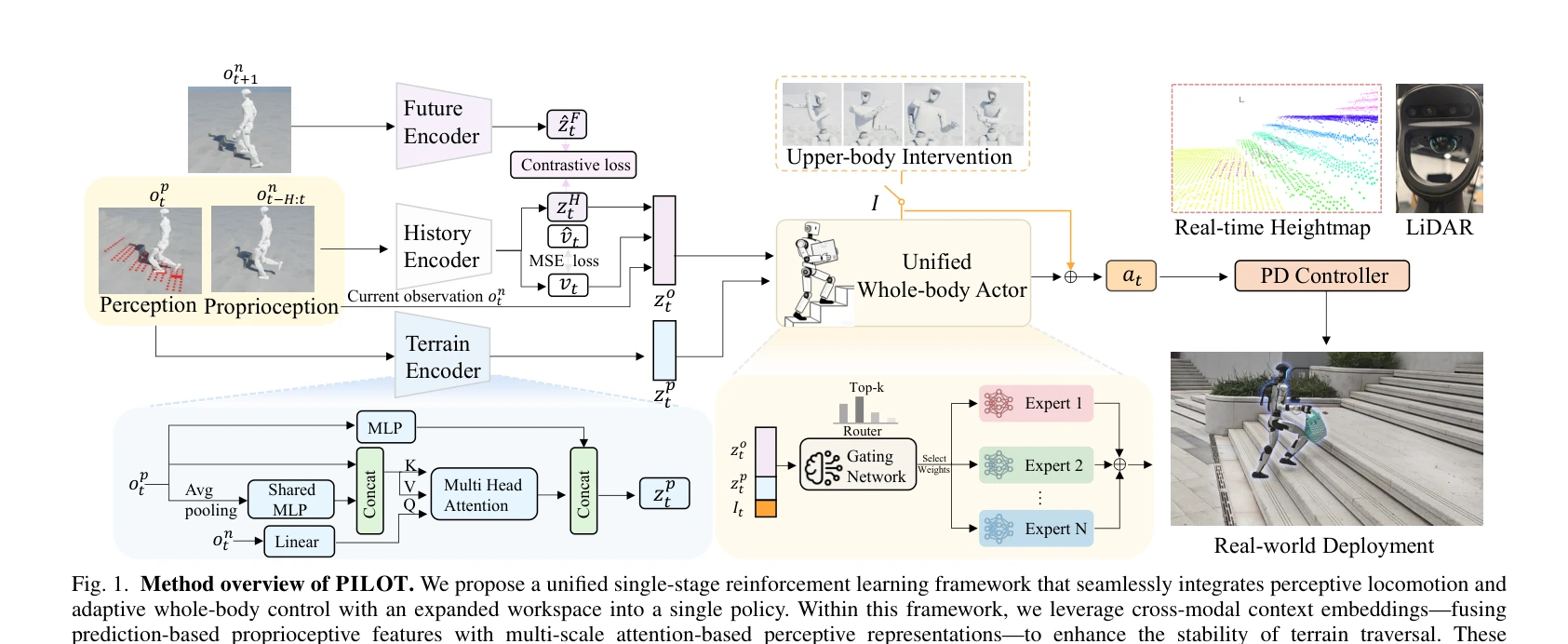
Fig. 1. Method overview of PILOT. We propose a unified single-stage reinforcement learning framework that seamlessly int
PILOT는 humanoid robot의 loco-manipulation을 위한 통합 단계 RL 프레임워크로, 지각 기반 locomotion과 전신 제어를 단일 policy로 통합하여 비정형 지형에서 안정적인 작업 실행을 가능하게 한다.