Essence
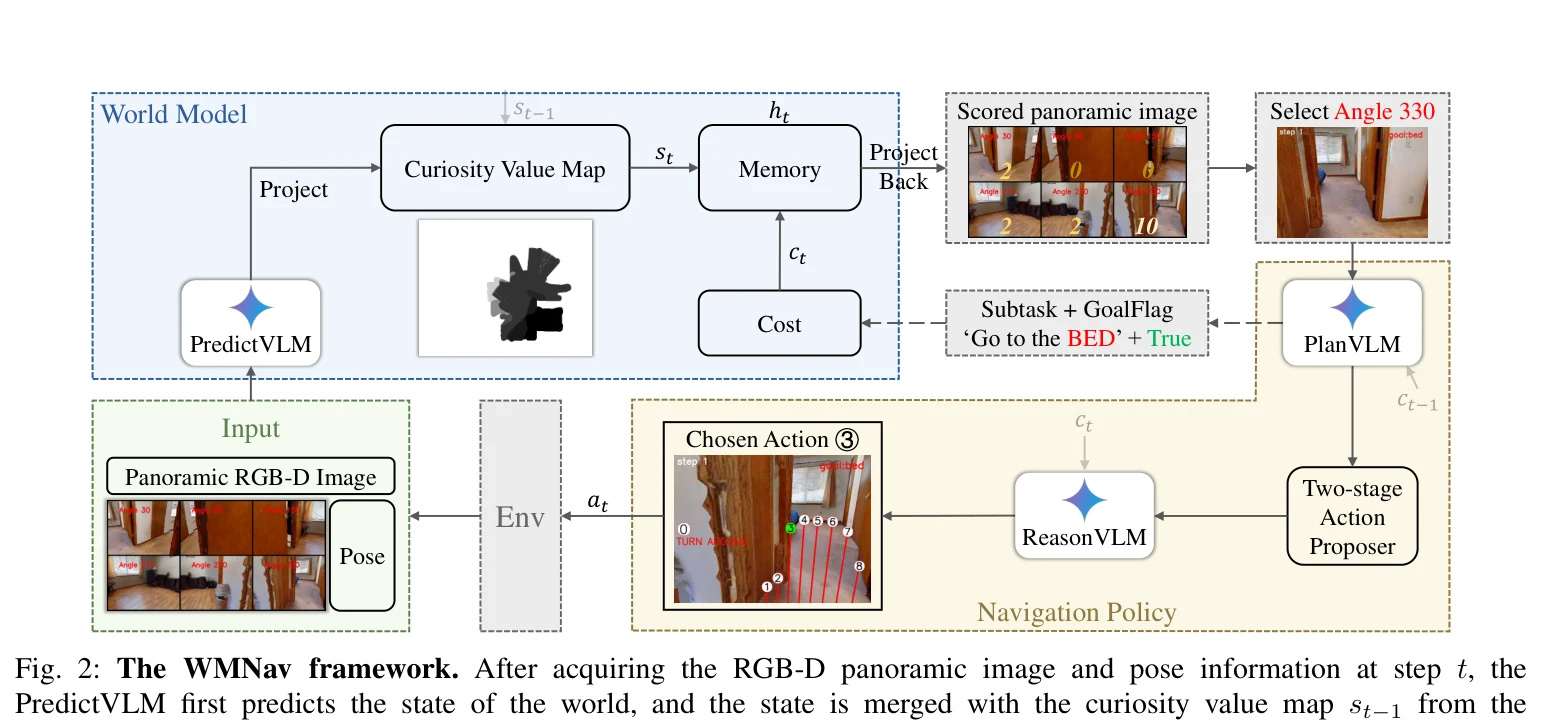
Fig. 2: The WMNav framework. After acquiring the RGB-D panoramic image and pose information at step t, the
Vision-Language Model을 기반으로 한 world model을 설계하여 Object Goal Navigation 작업에서 미래 상태를 예측하고 메모리를 통해 정책을 개선하는 WMNav 프레임워크를 제안한다. Curiosity Value Map이라는 온라인 유지 메모리 구조와 두 단계 행동 제안 전략으로 VLM의 hallucination을 완화하면서 탐색 효율성을 향상시킨다.