Essence
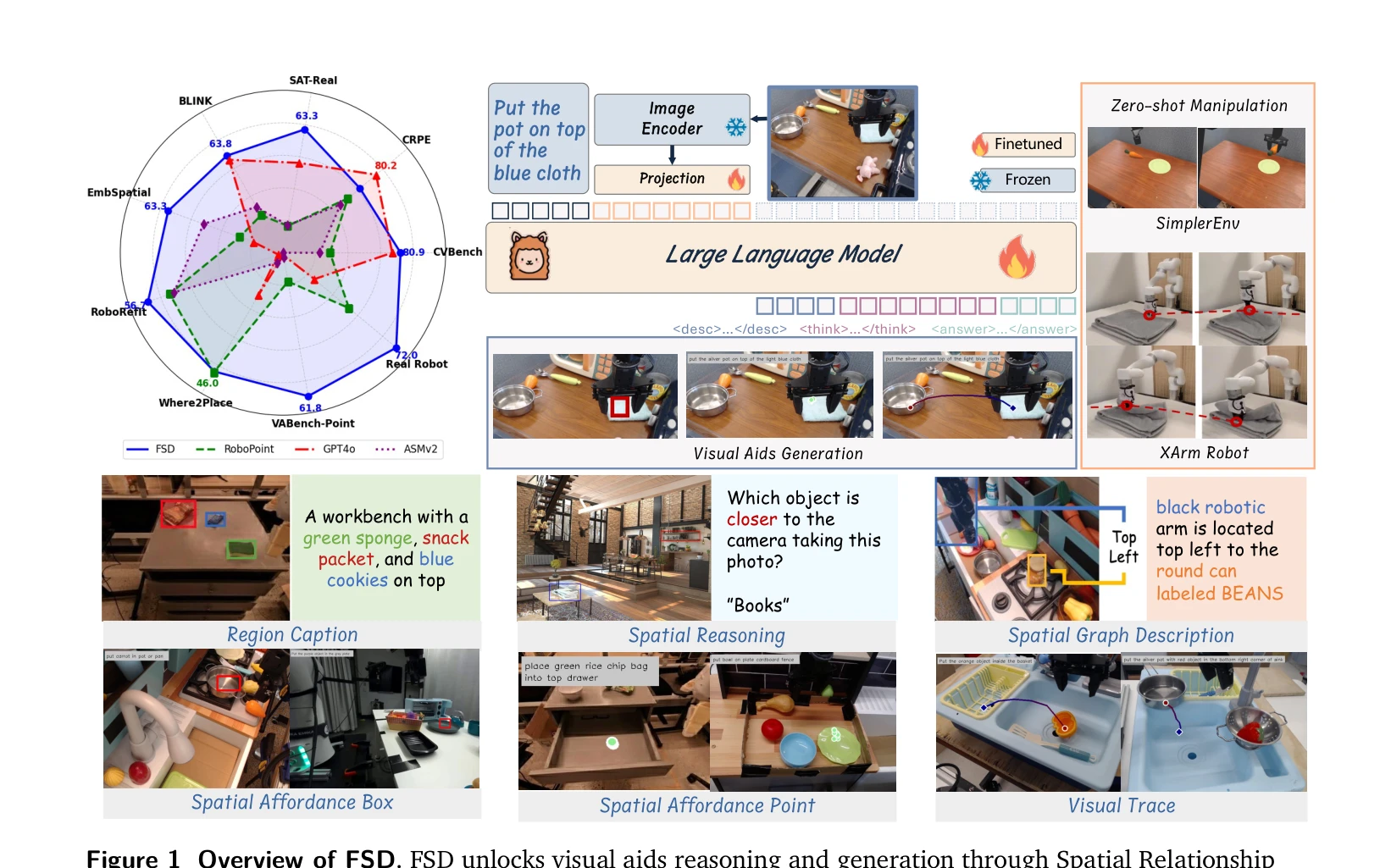
Figure 1 Overview of FSD. FSD unlocks visual aids reasoning and generation through Spatial Relationship
FSD는 Vision-Language Model에 spatial relationship reasoning을 통한 중간 표현(visual aids) 생성을 추가하여, 로봇 조작에서 zero-shot 일반화 성능을 획기적으로 향상시키는 모델이다.
저자: Yifu Yuan, Haiqin Cui, Yibin Chen, Zibin Dong, Fei Ni, Longxin Kou, Jinyi Liu, Pengyi Li, Yan Zheng, Jianye Hao | 날짜: 2025-05-13 | URL: https://arxiv.org/abs/2505.08548 📄 PDF
Figure 1 Overview of FSD. FSD unlocks visual aids reasoning and generation through Spatial Relationship
FSD는 Vision-Language Model에 spatial relationship reasoning을 통한 중간 표현(visual aids) 생성을 추가하여, 로봇 조작에서 zero-shot 일반화 성능을 획기적으로 향상시키는 모델이다.
Figure 1 Overview of FSD. FSD unlocks visual aids reasoning and generation through Spatial Relationship
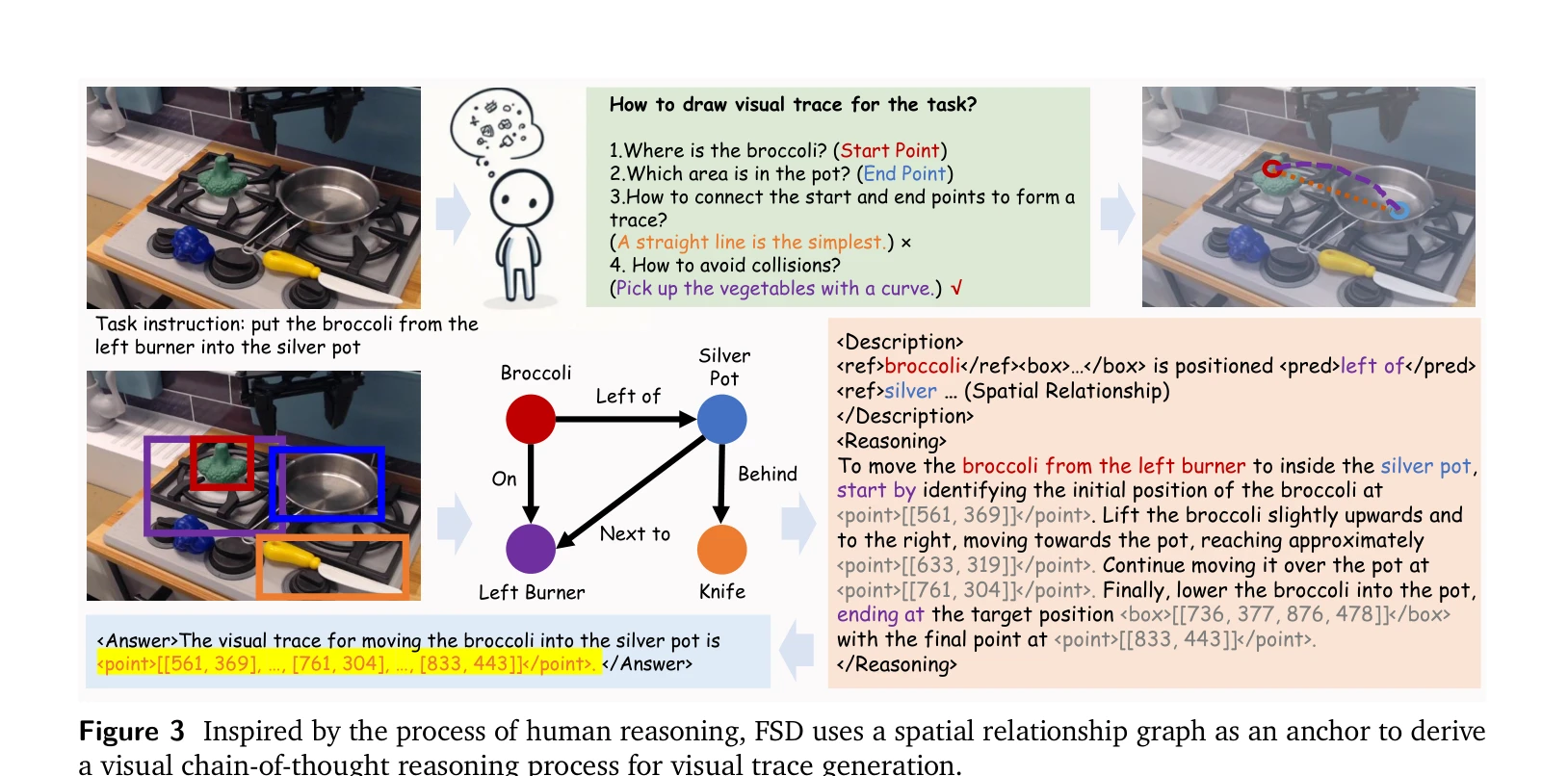
Figure 3 Inspired by the process of human reasoning, FSD uses a spatial relationship graph as an anchor to derive
총평: FSD는 spatial reasoning을 통한 visual aids 생성으로 로봇 조작의 일반화 문제를 창의적으로 해결하며, 다양한 벤치마크와 실제 로봇 환경에서 검증된 우수한 성과를 보여준다. ICLR 2026 발표 논문으로서 embodied AI의 중요한 진전을 제시한다.