저자: Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, Ya-Qin Zhang, Jiangmiao Pang, Jingjing Liu, Tai Wang, Xianyuan Zhan | 날짜: 2025-10-11 | URL: https://arxiv.org/abs/2510.10274 📄 PDF
Essence
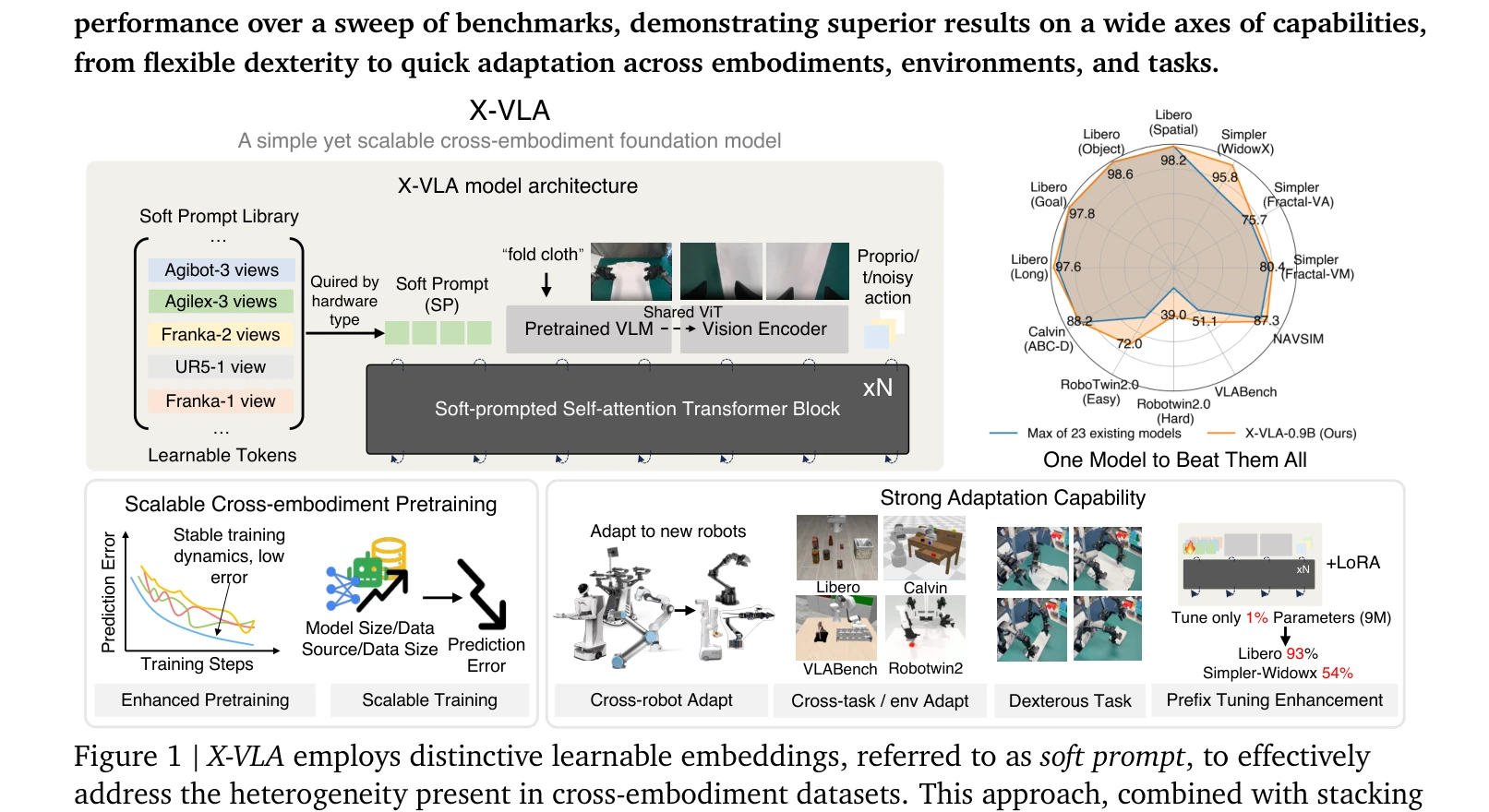
Figure 1 | X-VLA employs distinctive learnable embeddings, referred to as soft prompt, to effectively
X-VLA는 소프트 프롬프트(Soft Prompt) 기법을 도입하여 이질적인 로봇 플랫폼 간 cross-embodiment 학습을 효과적으로 처리하는 scalable Vision-Language-Action 모델이다. 0.9B 파라미터 규모로 6개 시뮬레이션 벤치마크와 3개 실로봇에서 SOTA 성능을 달성한다.
Evaluation
Novelty: 4/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: X-VLA는 soft prompt를 통한 우아하고 효율적인 cross-embodiment 처리 방식으로 VLA 분야의 중요한 진전을 이룬다. 파라미터 효율성과 광범위한 실증 평가를 통해 실제 로봇 응용 분야에서의 높은 실용성을 입증하며, flow-matching 기반 아키텍처의 안정성과 확장성은 향후 generalist 로봇 모델 개발의 주요 방향을 제시한다.