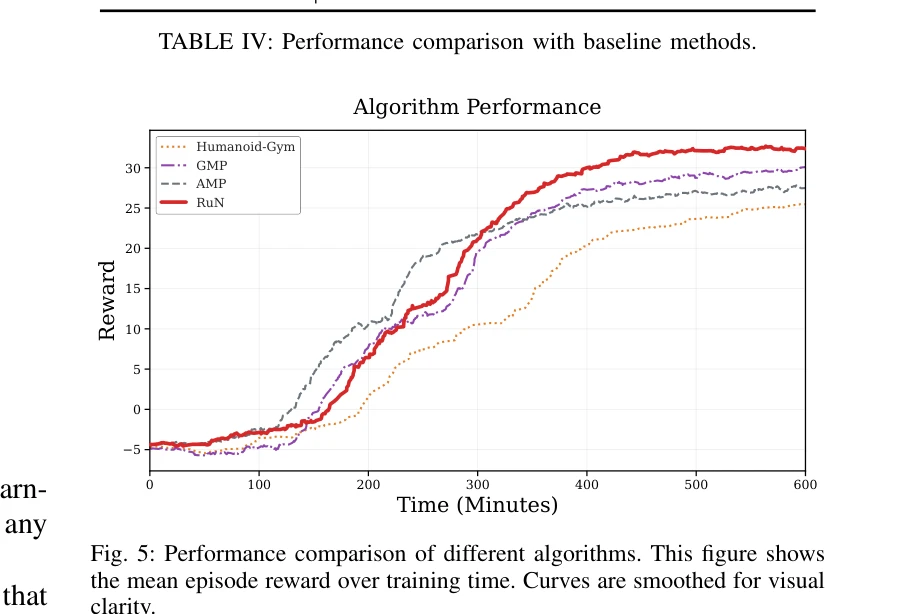
Essence
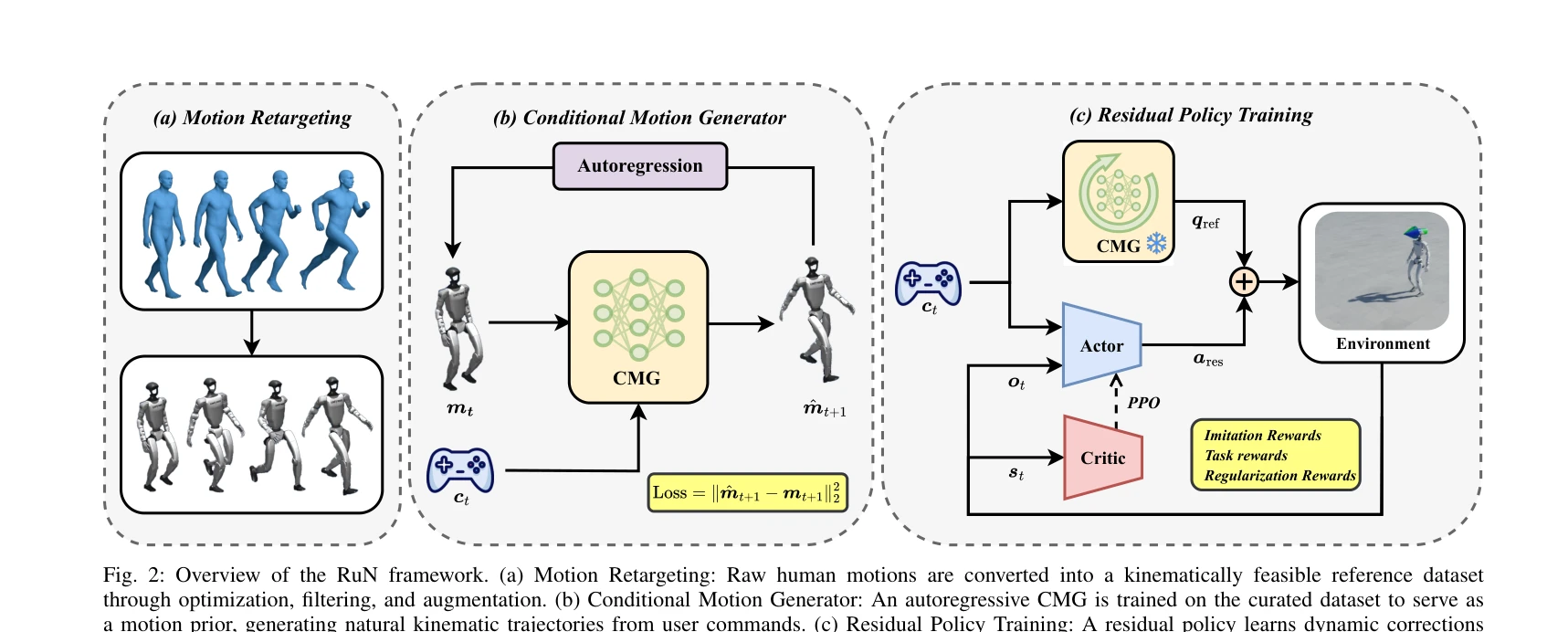
Fig. 2: Overview of the RuN framework. (a) Motion Retargeting: Raw human motions are converted into a kinematically feas
RuN은 Conditional Motion Generator를 통한 운동학적 모션 프라이어와 강화학습 기반 residual policy를 분리하여, 인형로봇의 자연스러운 보행-달리기 전환을 실현하는 decoupled residual learning 프레임워크이다.