Essence
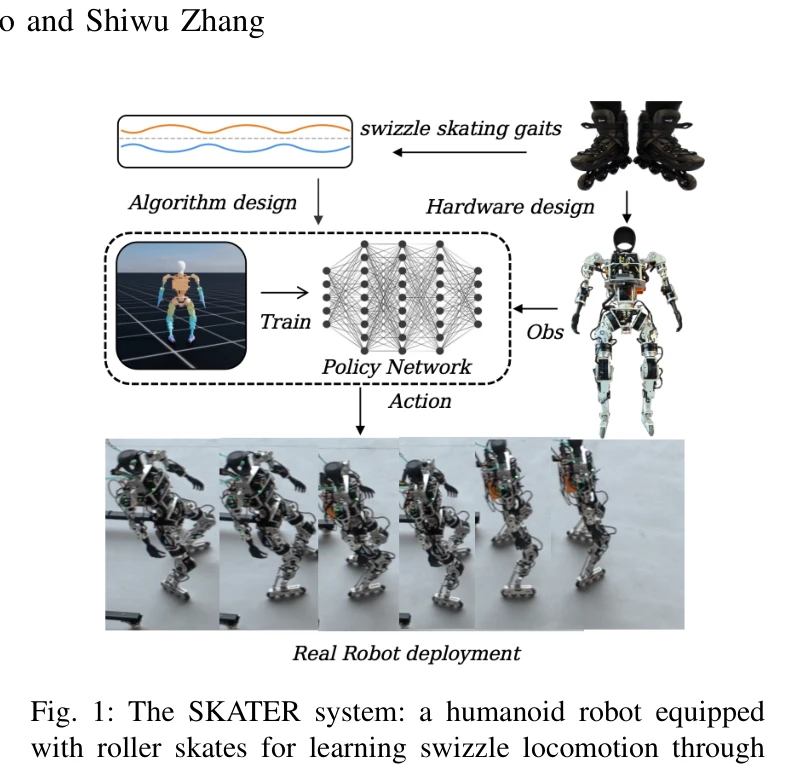
Fig. 1: The SKATER system: a humanoid robot equipped
휴머노이드 로봇의 발에 4개의 수동 바퀴를 장착하고 Deep Reinforcement Learning을 통해 롤러스케이팅 스위즐 보행을 학습시켜 전통적인 보행 대비 충격력 75.86%, 에너지 소비 63.34% 감소를 달성했다.
저자: Junchi Gu, Feiyang Yuan, Weize Shi, Tianchen Huang, Haopeng Zhang, Xiaohu Zhang, Yu Wang, Wei Gao, Shiwu Zhang | 날짜: 2026-01-08 | URL: https://arxiv.org/abs/2601.04948 📄 PDF
Fig. 1: The SKATER system: a humanoid robot equipped
휴머노이드 로봇의 발에 4개의 수동 바퀴를 장착하고 Deep Reinforcement Learning을 통해 롤러스케이팅 스위즐 보행을 학습시켜 전통적인 보행 대비 충격력 75.86%, 에너지 소비 63.34% 감소를 달성했다.
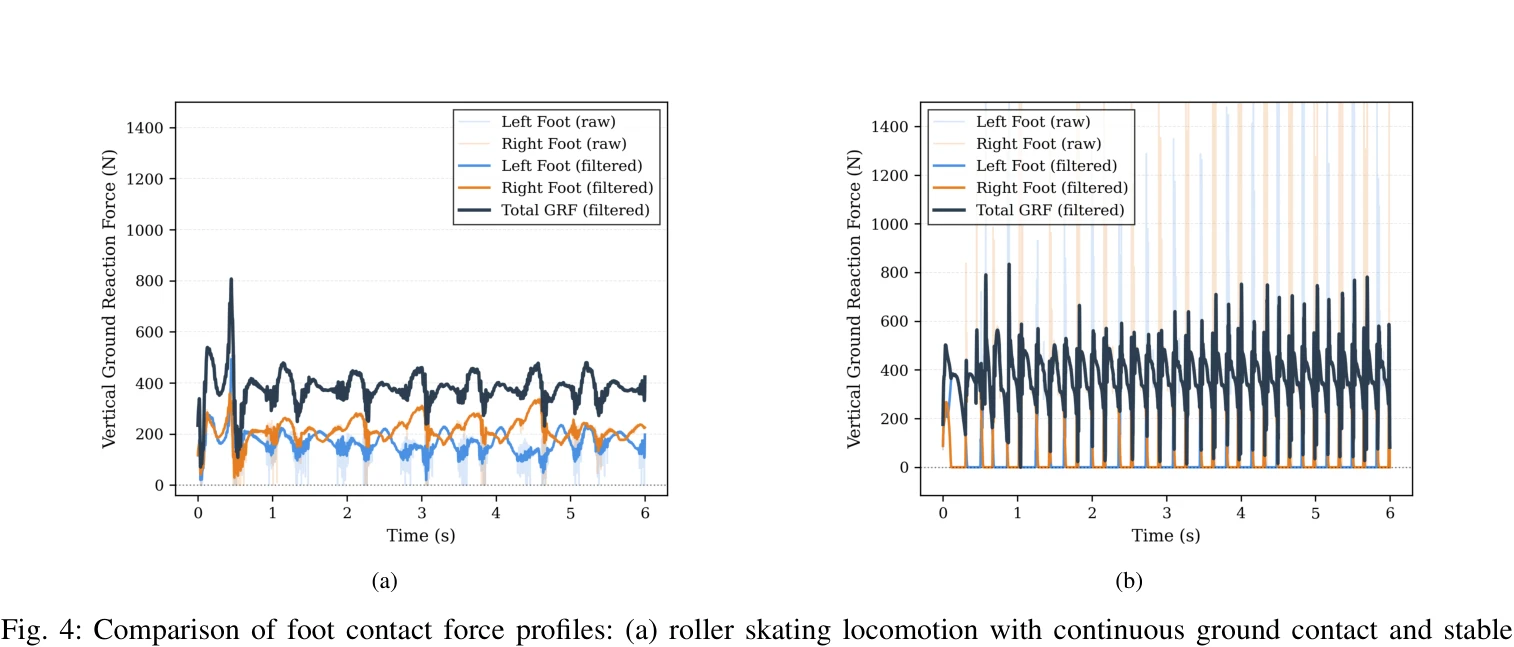
Fig. 4: Comparison of foot contact force profiles: (a) roller skating locomotion with continuous ground contact and stab
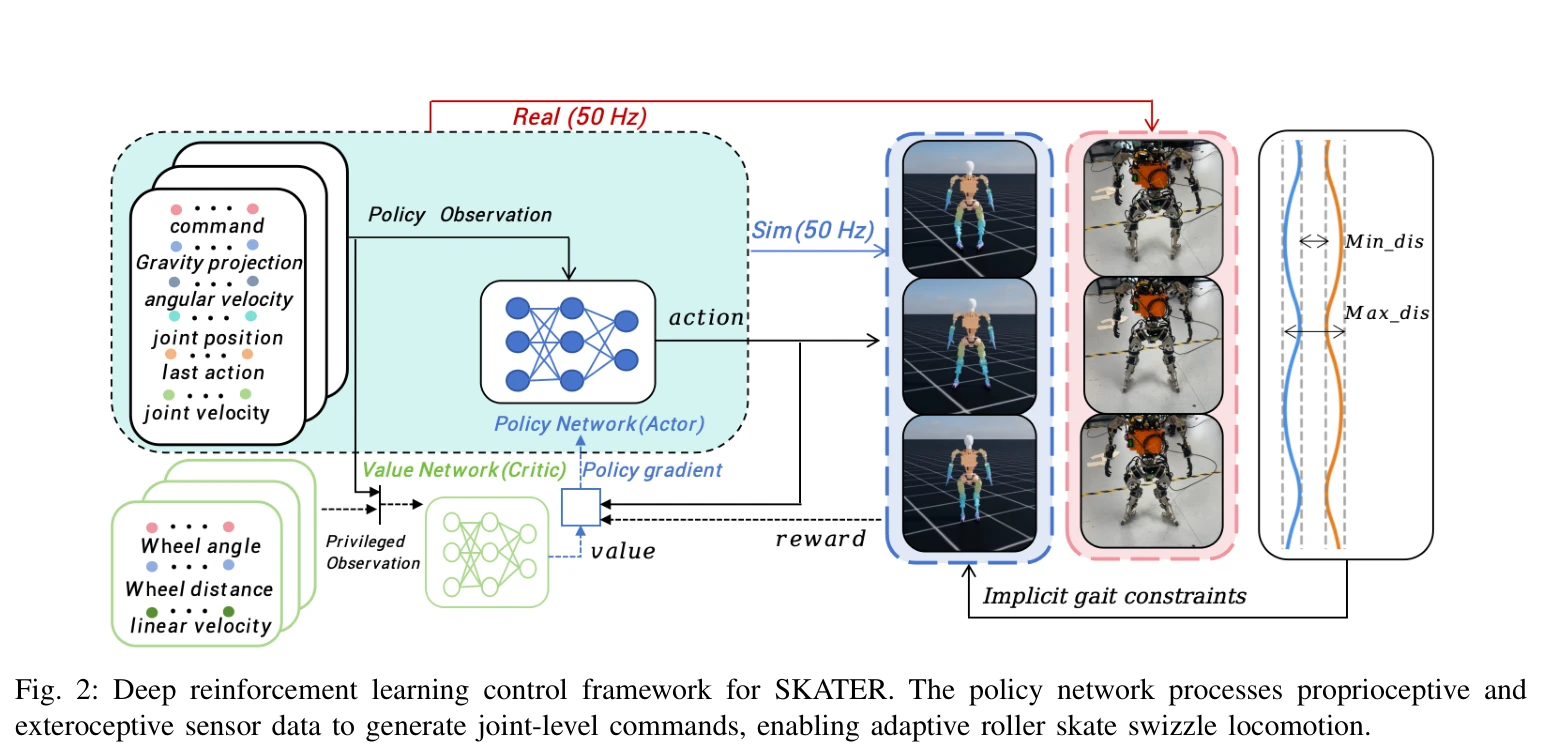
Fig. 2: Deep reinforcement learning control framework for SKATER. The policy network processes proprioceptive and
총평: 휴머노이드 로봇의 에너지 효율과 관절 수명 향상을 위해 롤러스케이팅이라는 창의적인 솔루션을 제시하고, DRL 기반 제어 프레임워크를 통해 현실적인 구현을 달성한 혁신적 연구이다. 85~76% 수준의 높은 성능 개선과 sim-to-real 전이의 성공은 로봇 운동 제어 분야에 실질적 기여를 한다.