Essence
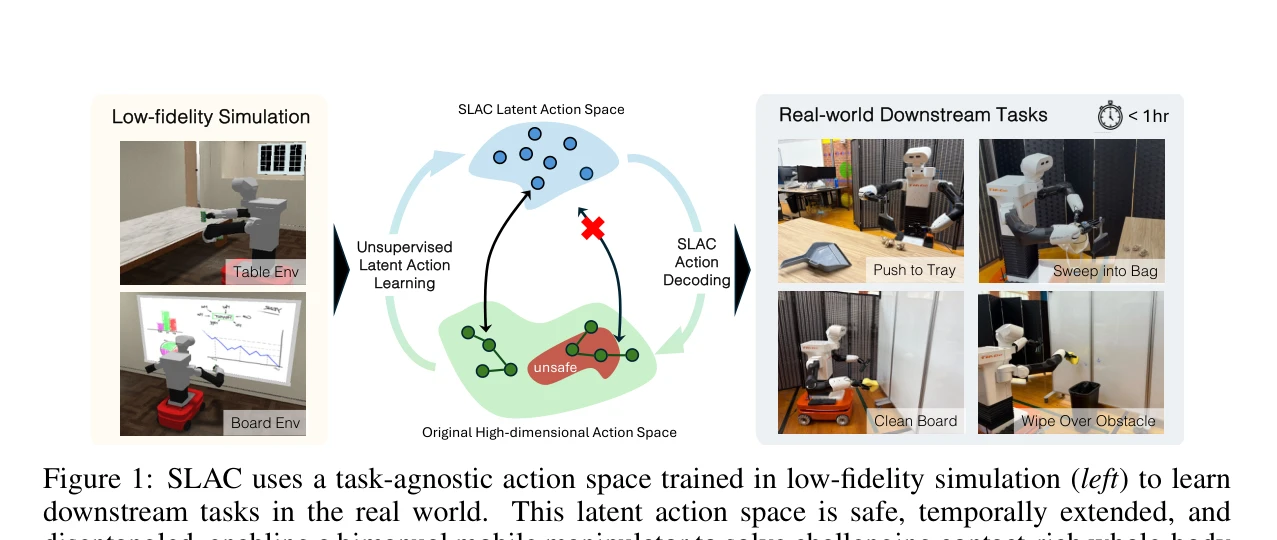
Figure 1: SLAC uses a task-agnostic action space trained in low-fidelity simulation (left) to learn
SLAC는 저충실도 시뮬레이터에서 학습한 task-agnostic 잠재 행동 공간을 사용하여 고자유도 모바일 매니퓨레이터가 실제 환경에서 효율적이고 안전하게 강화학습으로 접촉이 풍부한 전신 조작 작업을 학습할 수 있게 한다.
저자: Jiaheng Hu, Peter Stone, Roberto Martín-Martín | 날짜: 2025-06-04 | URL: https://arxiv.org/abs/2506.04147 📄 PDF
Figure 1: SLAC uses a task-agnostic action space trained in low-fidelity simulation (left) to learn
SLAC는 저충실도 시뮬레이터에서 학습한 task-agnostic 잠재 행동 공간을 사용하여 고자유도 모바일 매니퓨레이터가 실제 환경에서 효율적이고 안전하게 강화학습으로 접촉이 풍부한 전신 조작 작업을 학습할 수 있게 한다.
Figure 1: SLAC uses a task-agnostic action space trained in low-fidelity simulation (left) to learn
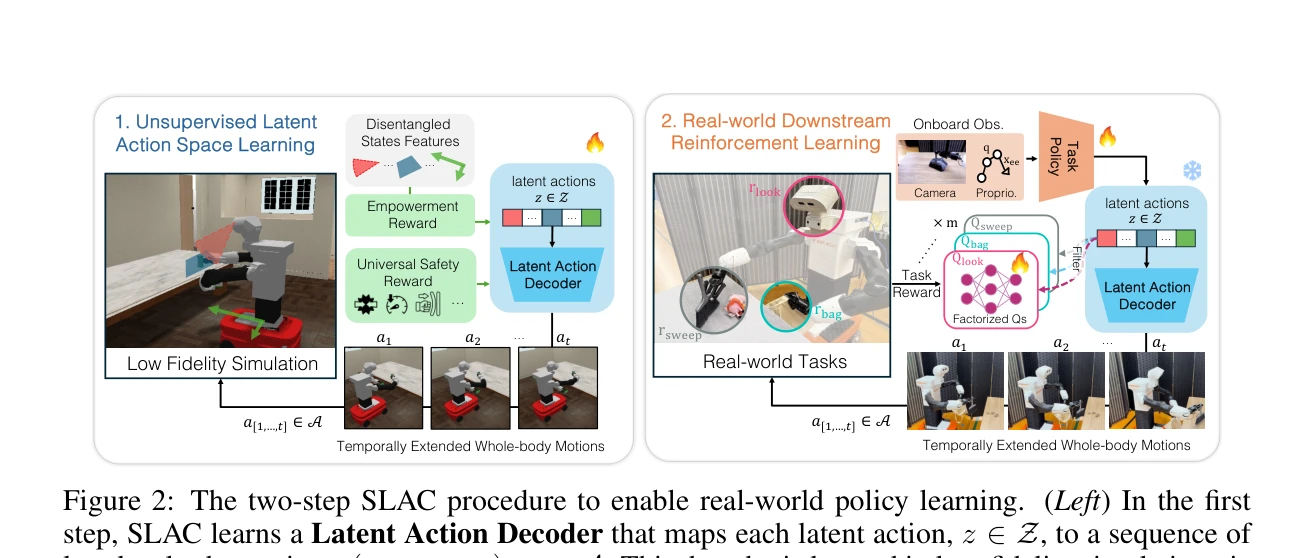
Figure 2: The two-step SLAC procedure to enable real-world policy learning. (Left) In the first
총평: SLAC는 저충실도 시뮬레이션 기반 latent action space pretraining과 실제 환경 강화학습을 결합하여 고자유도 모바일 매니퓨레이터의 복잡한 접촉 조작 작업을 안전하고 효율적으로 학습할 수 있게 하는 혁신적인 접근법을 제시하며, 1시간 미만의 실제 상호작용만으로 의미 있는 성과를 달성함으로써 실제 로봇 학습의 실용성을 크게 향상시킨다.