Essence
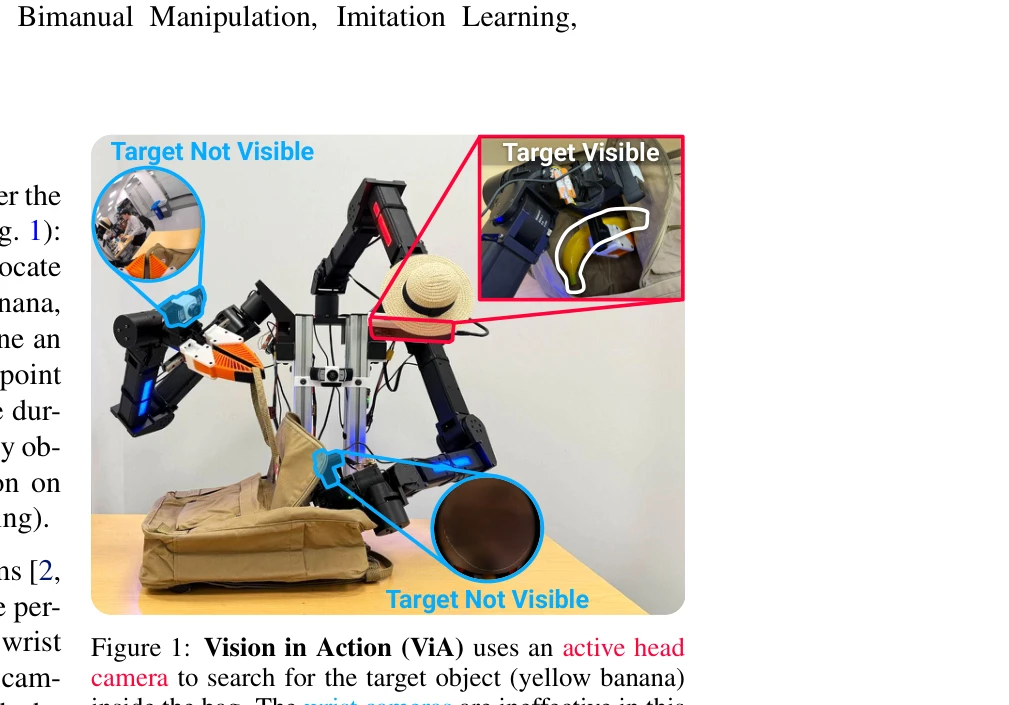
Figure 1: Vision in Action (ViA) uses an active head
ViA는 6-DoF 로봇 넥과 VR 텔레오퍼레이션 인터페이스를 통해 인간의 능동적 지각 전략을 직접 학습하여 이중팔 조작 로봇의 성능을 향상시키는 시스템이다.
저자: Haoyu Xiong, Xiaomeng Xu, Jimmy Wu, Yifan Hou, Jeannette Bohg, Shuran Song | 날짜: 2025-06-18 | URL: https://arxiv.org/abs/2506.15666 📄 PDF
Figure 1: Vision in Action (ViA) uses an active head
ViA는 6-DoF 로봇 넥과 VR 텔레오퍼레이션 인터페이스를 통해 인간의 능동적 지각 전략을 직접 학습하여 이중팔 조작 로봇의 성능을 향상시키는 시스템이다.
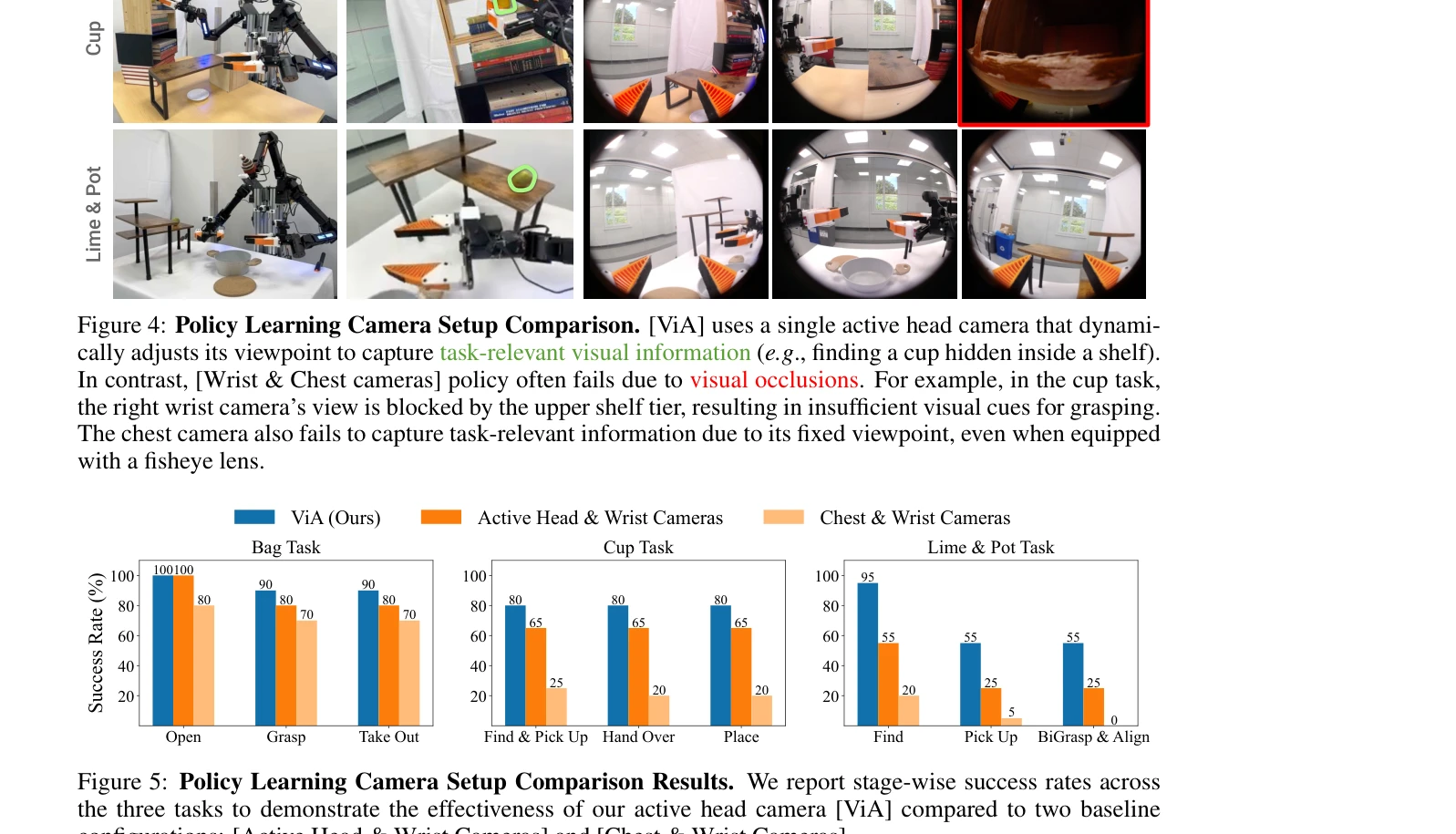
Figure 5: Policy Learning Camera Setup Comparison Results. We report stage-wise success rates across
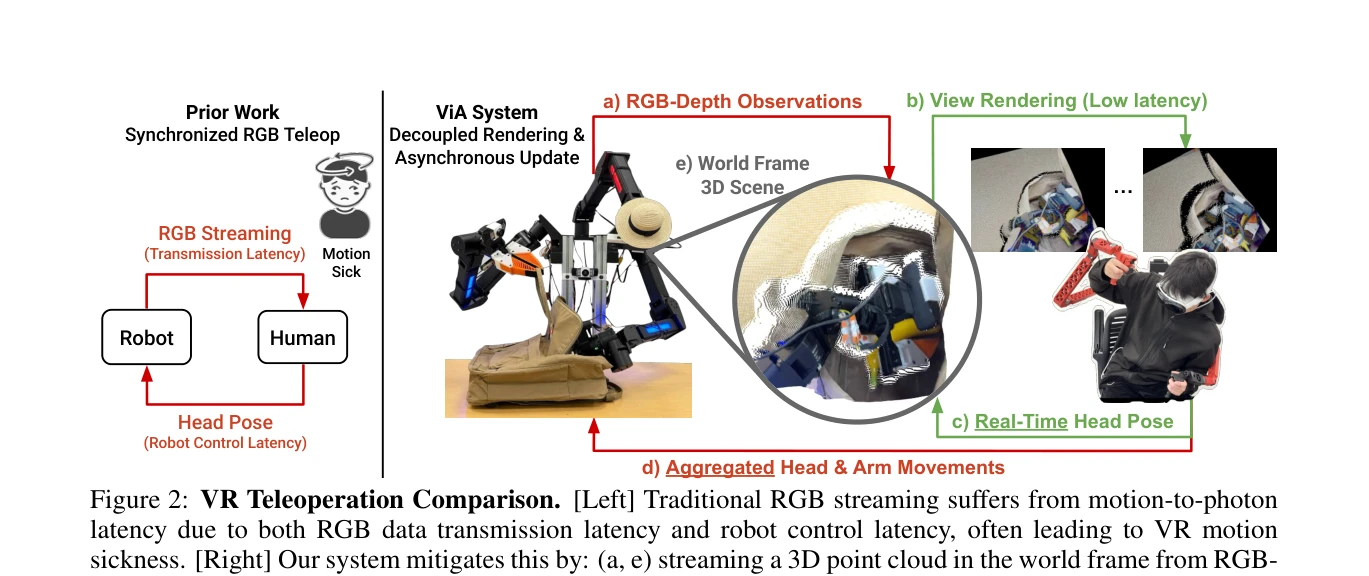
Figure 2: VR Teleoperation Comparison. [Left] Traditional RGB streaming suffers from motion-to-photon
총평: ViA는 능동적 지각, VR 텔레오퍼레이션, 이중팔 조작을 효과적으로 통합한 혁신적 시스템으로, 중간 3D 표현을 통한 지연 시간 해결과 공유 관찰 공간 개념이 특히 창의적이며, 시각적 폐색이 있는 복잡한 실제 작업에서 실질적인 성능 향상을 달성했다.