저자: Bin Cao, Sipeng Zheng, Ye Wang, Lujie Xia, Qianshan Wei, Qin Jin, Jing Liu, Zongqing Lu | 날짜: 2025-08-11 | URL: https://arxiv.org/abs/2508.07863 📄 PDF
Essence

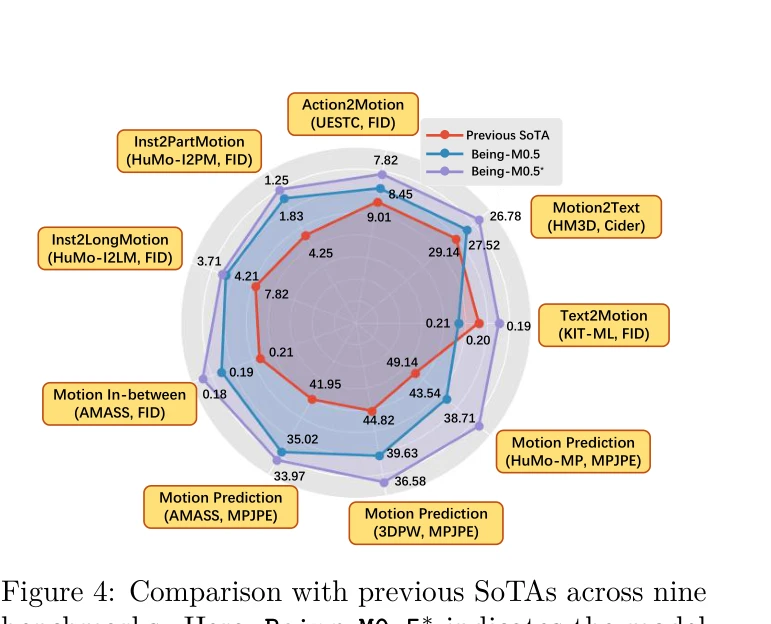
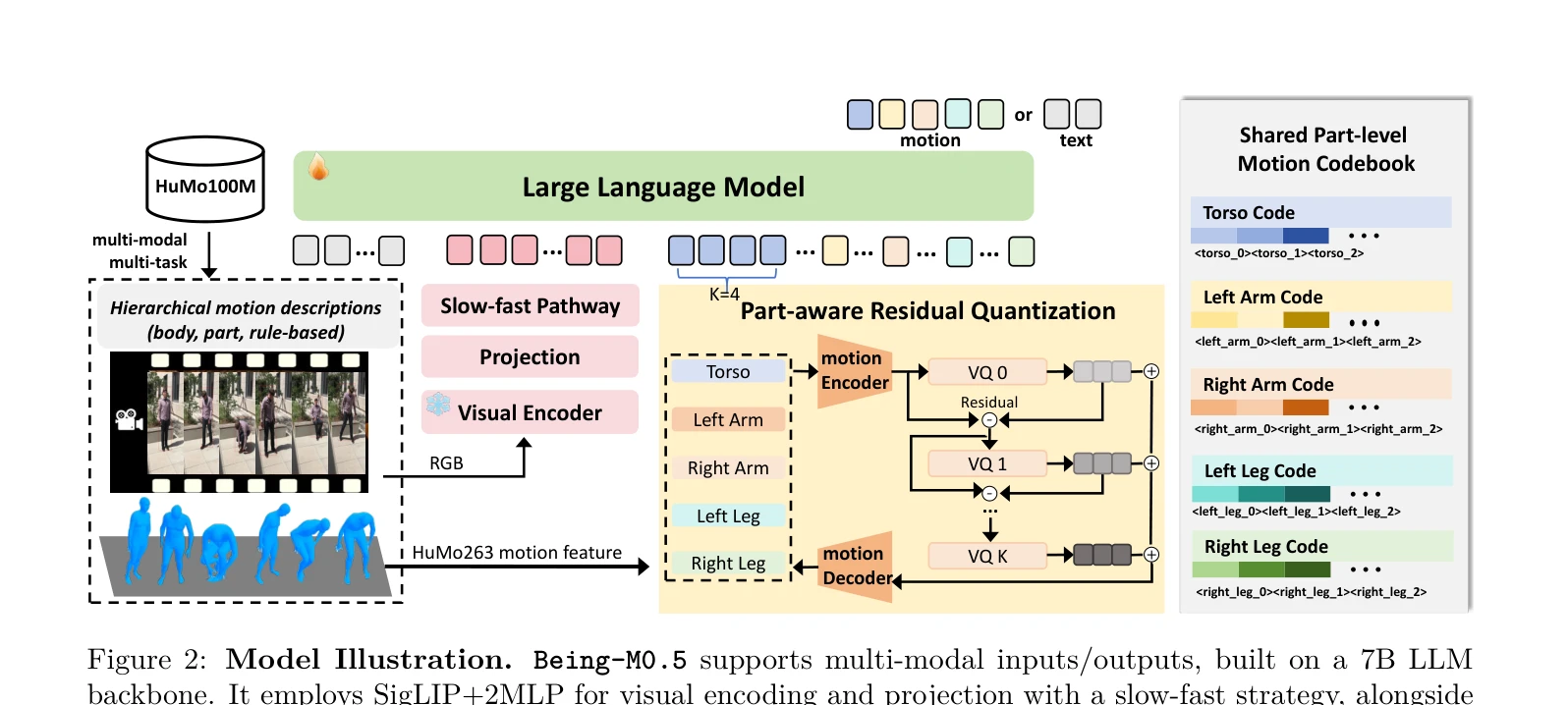
Figure 1: Leveraging our million-scale dataset HuMo100M, we present Being-M0.5, the first real-time, control-
Being-M0.5는 HuMo100M이라는 백만 규모의 대규모 데이터셋을 기반으로 한 최초의 실시간 제어 가능 vision-language-motion model로, part-aware residual quantization을 통해 신체 각 부위에 대한 세밀한 제어를 가능하게 한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: Being-M0.5는 HuMo100M과 part-aware residual quantization이라는 두 가지 주요 혁신을 통해 motion generation의 제어 가능성과 실시간 성능 문제를 동시에 해결하며, 대규모 데이터셋과 모델 설계 통찰력으로 실제 응용 배포의 새로운 기준을 제시한다.