저자: Hao Luo, Yicheng Feng, Wanpeng Zhang, Sipeng Zheng, Ye Wang, Haoqi Yuan, Jiazheng Liu, Chaoyi Xu, Qin Jin, Zongqing Lu | 날짜: 2025-07-21 | URL: https://arxiv.org/abs/2507.15597 📄 PDF
Essence

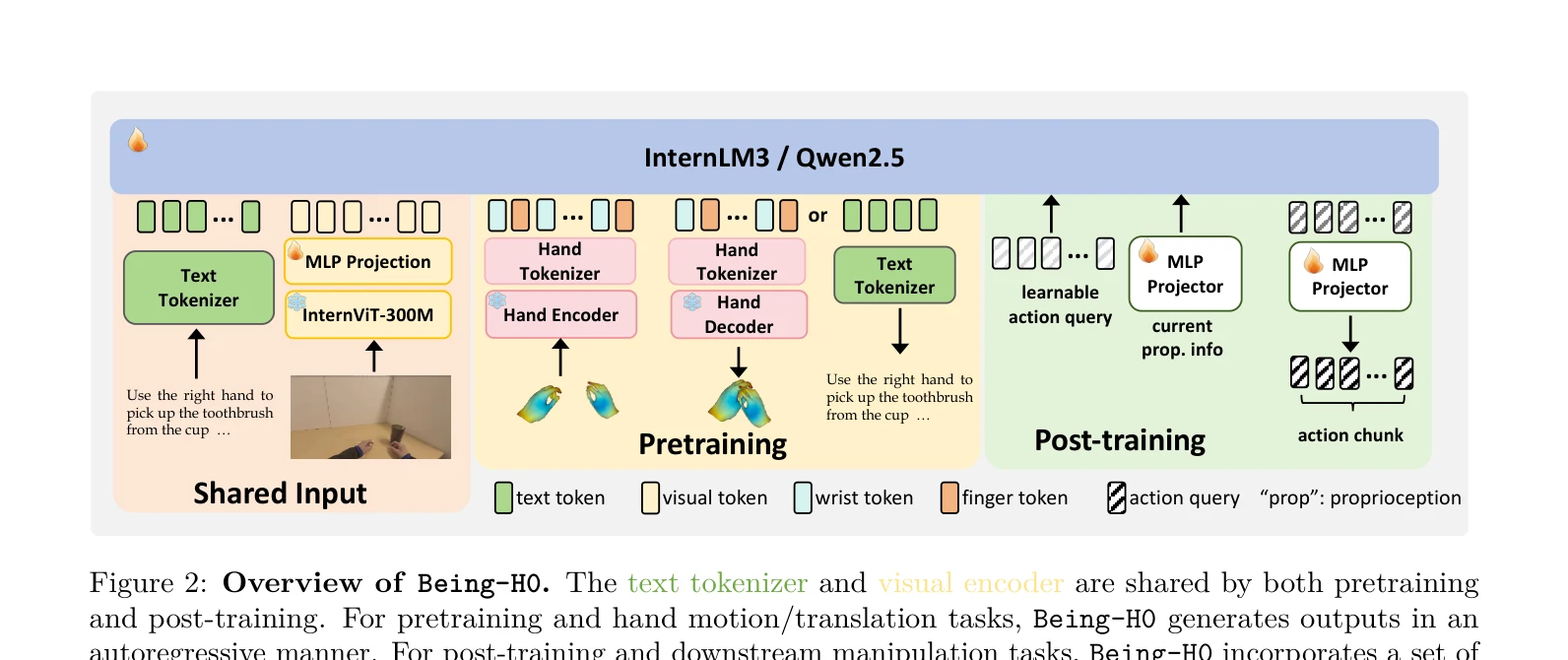
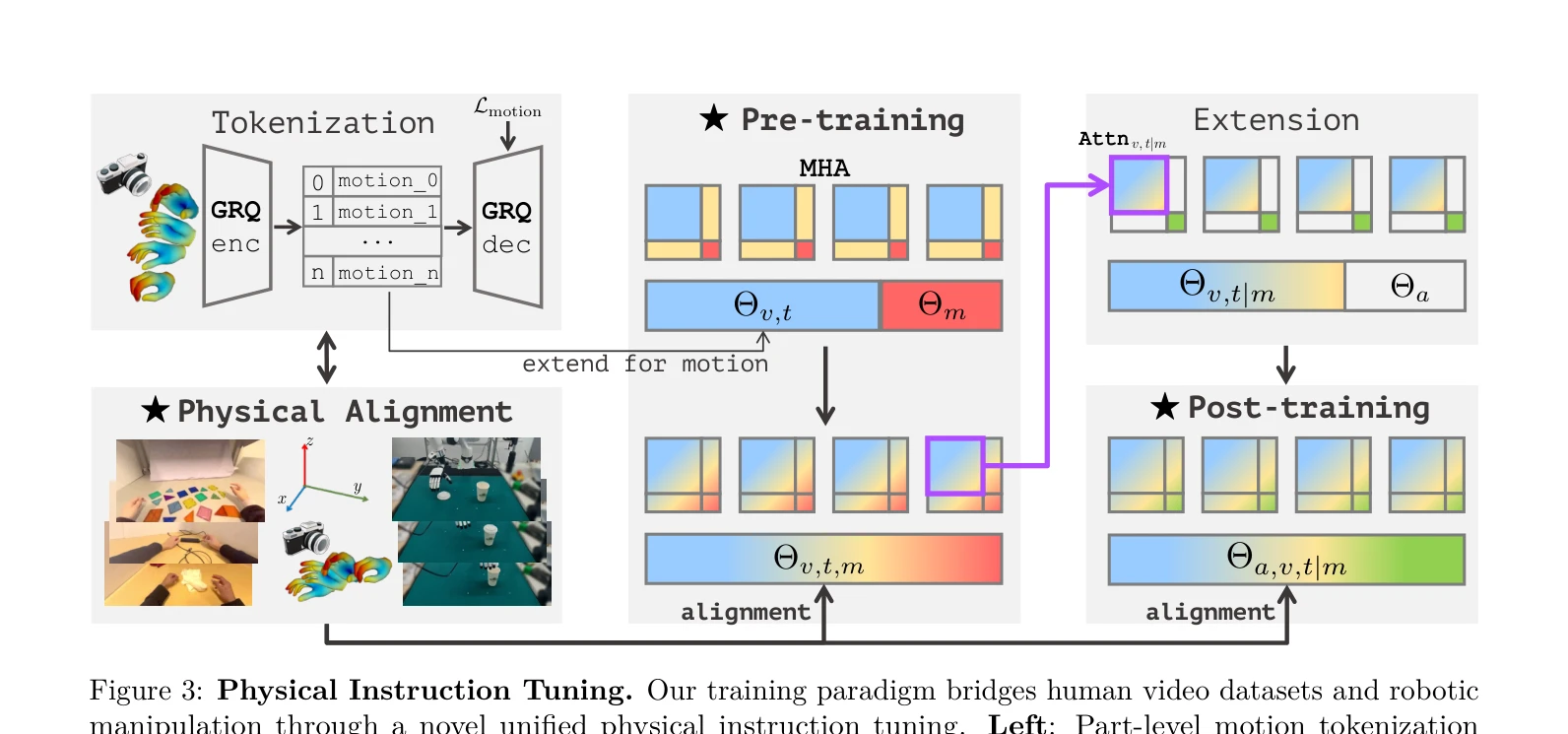
Figure 1: Being-H0 acquires dexterous manipulation skills by learning from large-scale human videos in the
Being-H0는 대규모 인간 비디오로부터 학습한 민첩한 Vision-Language-Action 모델로, physical instruction tuning 패러다임을 통해 인간의 손 동작을 명시적으로 모델링하여 로봇 조작 작업으로 전이한다.
Evaluation
Novelty: 4/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: Being-H0는 대규모 인간 비디오로부터 민첩한 로봇 조작을 학습하는 새로운 패러다임을 제시하며, physical instruction tuning과 part-level motion tokenization을 통해 기존 VLA의 데이터 부족 문제를 혁신적으로 해결한다. 명시적 동작 모델링 접근법과 UniHand 데이터셋은 로봇 공학 분야에 중요한 기여를 제공한다.