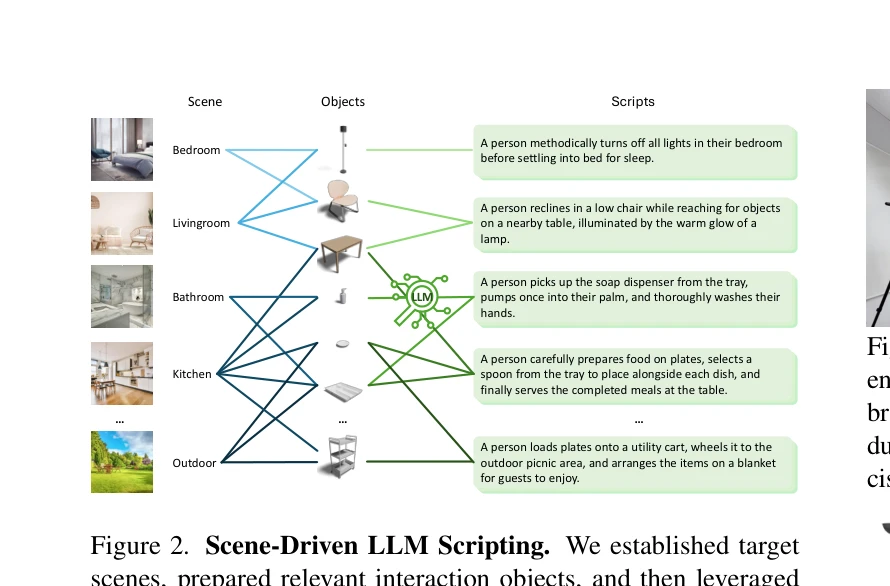
Essence
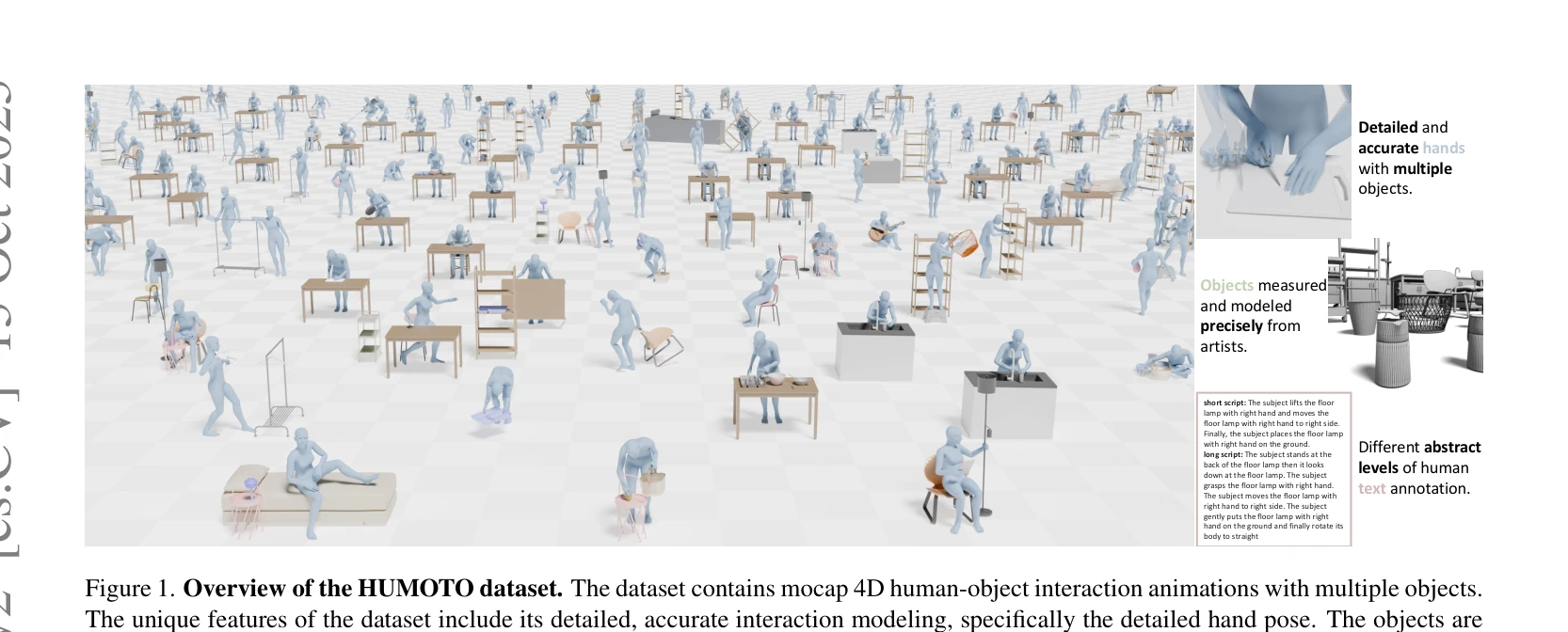
Figure 1. Overview of the HUMOTO dataset. The dataset contains mocap 4D human-object interaction animations with multipl
HUMOTO는 735개 시퀀스(7,875초)의 고충실도 모션캡처 4D 인간-객체 상호작용 데이터셋으로, 63개의 정밀 모델링 객체와 상세한 손 동작을 포함하며 LLM 기반 스크립팅과 다중센서 캡처로 복잡한 다중-객체 상호작용을 정확히 기록한다.