Essence

Fig. 1: Coordinated Humanoid Manipulation. We present a teleoperation system and a policy learning framework for
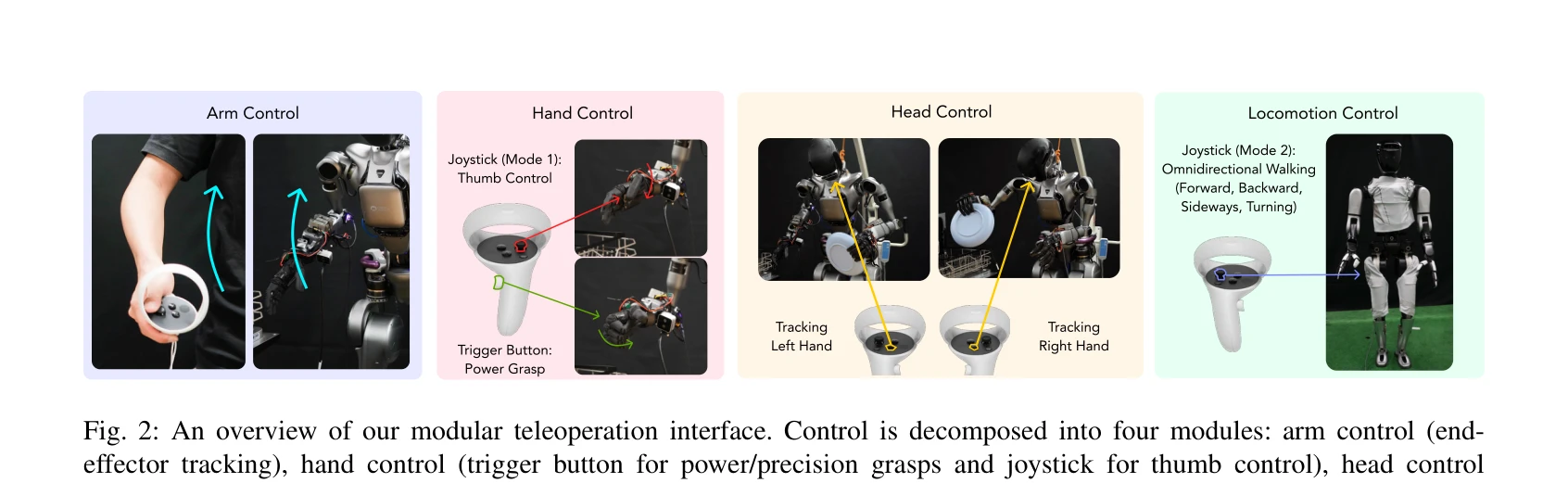
휴머노이드 로봇의 전신 협조 조작을 위해 모듈식 텔레오퍼레이션 인터페이스와 Choice Policy라는 모방 학습 방식을 결합한 시스템을 제시한다. Choice Policy는 다중 후보 행동을 생성하고 점수를 학습하여 멀티모달 행동을 효율적으로 모델링한다.