Essence

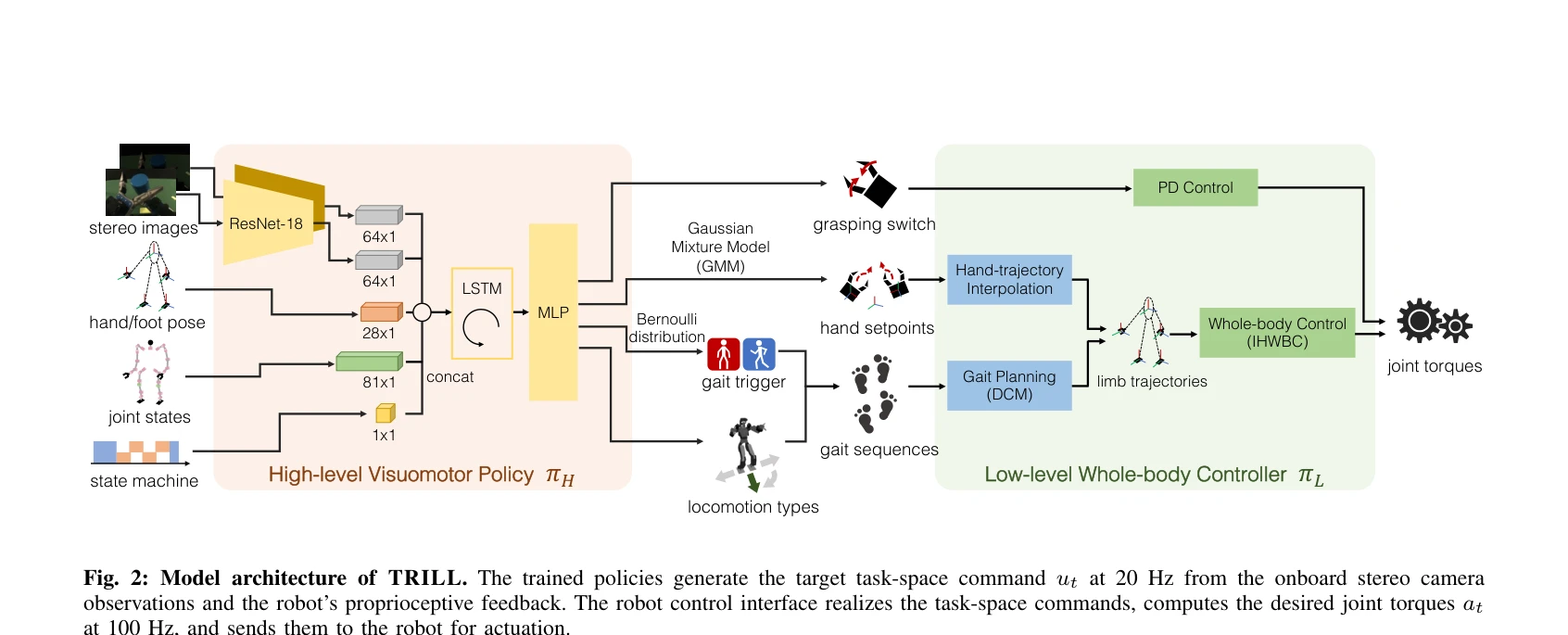
Fig. 1: Overview of TRILL. TRILL addresses the challenge of learning
본 논문은 VR 텔레오퍼레이션을 통해 수집한 인간 시연 데이터로부터 humanoid 로봇의 loco-manipulation 능력을 deep imitation learning으로 학습하는 TRILL 프레임워크를 제시한다. Whole-body control 기반의 계층적 정책 구조를 통해 높은 자유도 humanoid의 복잡한 동작을 데이터 효율적으로 학습할 수 있다.
Evaluation
Novelty: 4/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 본 논문은 humanoid loco-manipulation을 위한 데이터 효율적 deep imitation learning 방법을 제시하며, whole-body control과의 영리한 결합을 통해 높은 자유도 시스템의 안정성과 학습 효율성을 동시에 달성했다. 실제 humanoid 로봇에서 처음으로 성공적으로 복잡한 manipulation을 학습한 선도적 성과로, 앞으로 humanoid의 자율 능력 향상에 중요한 기여를 할 것으로 예상된다.