저자: Puyue Wang, Jiawei Hu, Yan Gao, Junyan Wang, Yu Zhang, Gillian Dobbie, Tao Gu, Wafa Johal, Ting Dang, Hong Jia | 날짜: 2026-02-04 | URL: https://arxiv.org/abs/2602.04412 📄 PDF
Essence
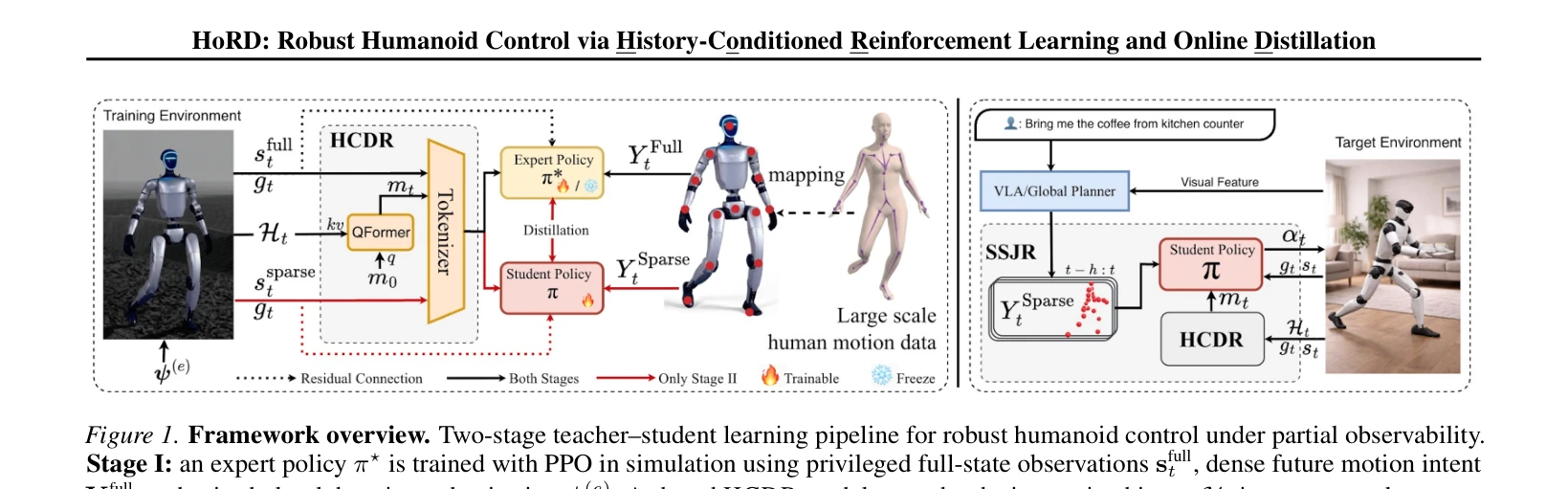
Figure 1. Framework overview. Two-stage teacher–student learning pipeline for robust humanoid control under partial obse
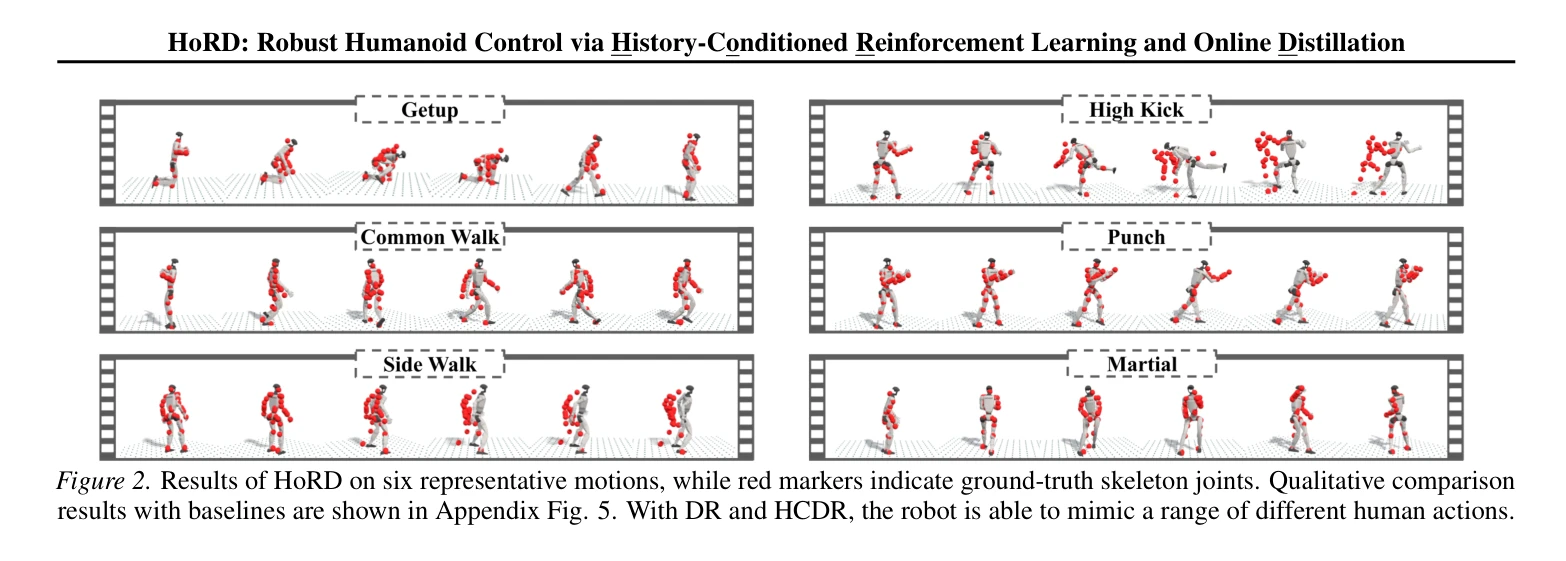
HoRD는 history-conditioned reinforcement learning과 online distillation을 결합한 두 단계 학습 프레임워크로, 휴머노이드 로봇이 도메인 시프트 상황에서 강건한 제어를 수행하도록 한다.
Evaluation
Novelty: 4/5 Technical Soundness: 4/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: HoRD는 history-conditioned 동역학 추론과 sparse 명령 처리라는 두 가지 핵심 혁신을 통해 휴머노이드 제어의 강건성과 일반화 문제를 효과적으로 해결하며, 광범위한 실험 검증과 데이터셋 공개로 실용적 가치를 입증한다.