Essence

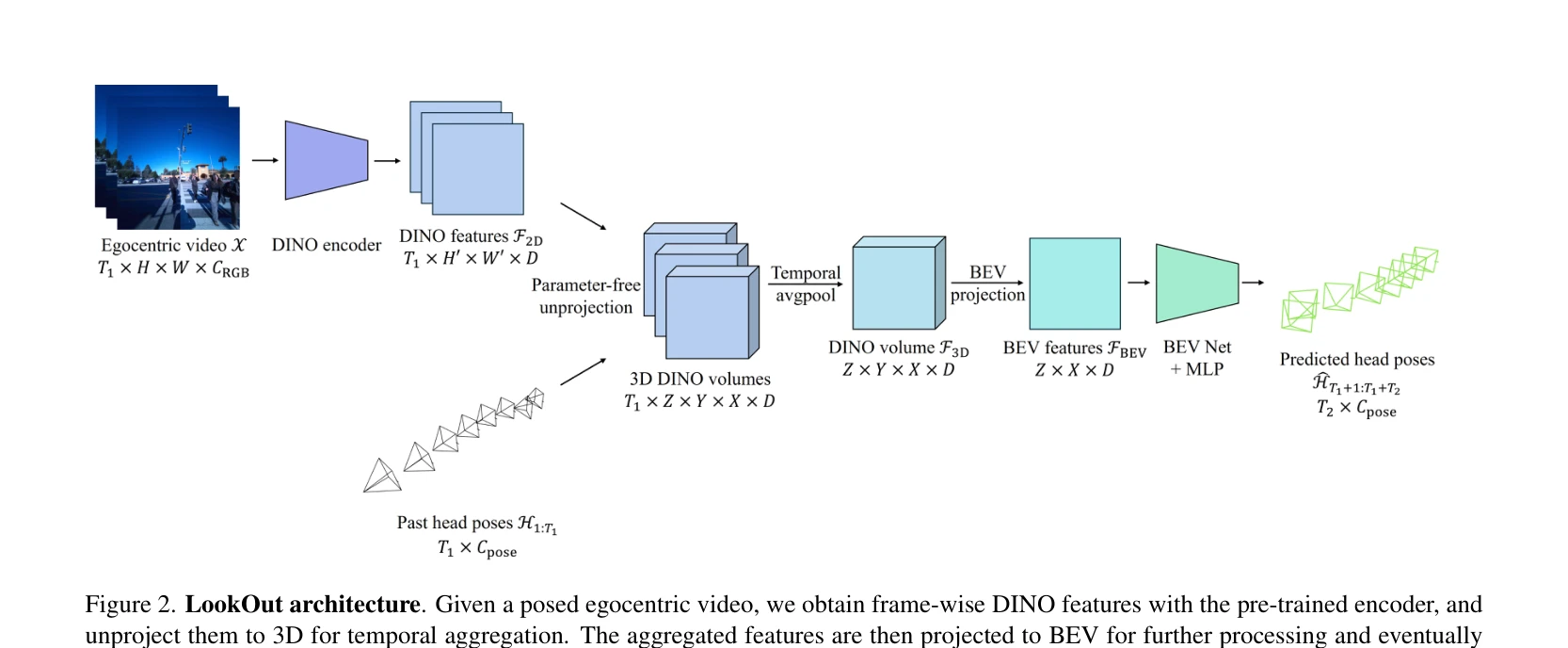
Figure 1. Problem formulation. Given a posed egocentric video (black-outlined frustums, with frames shown in detail on t
Project Aria 안경을 이용한 데이터 수집 파이프라인과 함께, 동적 장애물이 있는 실제 환경에서 egocentric 비디오로부터 미래의 6D 헤드 포즈(위치 및 회전)를 예측하는 LookOut 모델을 제안한다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 인간형 egocentric 네비게이션의 동적 환경 처리, 능동적 정보 수집 모델링, 그리고 실용적 데이터 수집 파이프라인을 종합적으로 해결한 포괄적 기여로, Project Aria를 활용한 혁신적 데이터 수집 방식과 현실성 높은 4시간 AND 데이터셋이 향후 연구에 큰 영향을 미칠 것으로 기대된다.