Essence

Fig. 1: Our system enables versatile, contact-rich, and dexterous humanoid manipulation. A: long-horizon, multi-stage ma
휴머노이드 로봇의 접촉-풍부한 조작을 위해 VR 텔레오퍼레이션 기반 데이터 수집과 터치 감각을 핵심 모달리티로 하는 Humanoid Transformer with Touch Dreaming (HTD)을 제안한다.
저자: Yaru Niu, Zhenlong Fang, Binghong Chen, Shuai Zhou, Revanth Senthilkumaran, Hao Zhang, Bingqing Chen, Chen Qiu, H. Eric Tseng, Jonathan Francis, Ding Zhao | 날짜: 2026-04-14 | URL: https://arxiv.org/abs/2604.13015 📄 PDF
Fig. 1: Our system enables versatile, contact-rich, and dexterous humanoid manipulation. A: long-horizon, multi-stage ma
휴머노이드 로봇의 접촉-풍부한 조작을 위해 VR 텔레오퍼레이션 기반 데이터 수집과 터치 감각을 핵심 모달리티로 하는 Humanoid Transformer with Touch Dreaming (HTD)을 제안한다.
Fig. 1: Our system enables versatile, contact-rich, and dexterous humanoid manipulation. A: long-horizon, multi-stage ma
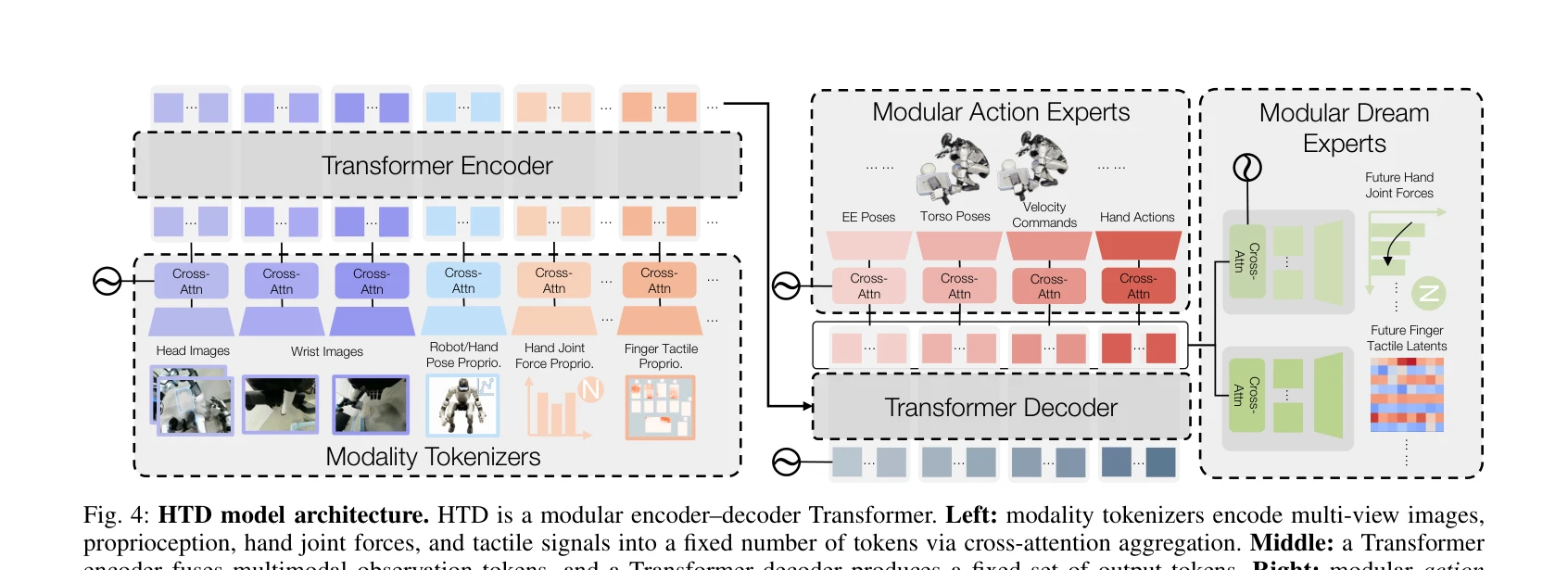
Fig. 4: HTD model architecture. HTD is a modular encoder–decoder Transformer. Left: modality tokenizers encode multi-vie
총평: 본 논문은 터치를 핵심 모달리티로 하는 Touch Dreaming 기법과 통합된 실세계 데이터 수집 시스템으로 휴머노이드 접촉-풍부한 조작의 실현 가능성을 강력하게 입증한다. 다섯 가지 다양한 실제 작업에서 90.9% 성능 개선을 달성하며, 잠재 공간 예측의 효과성을 명확히 보여주는 높은 질의 연구이다.