저자: Shivansh Patel, Xinchen Yin, Wenlong Huang, Shubham Garg, Hooshang Nayyeri, Li Fei-Fei, Svetlana Lazebnik, Yunzhu Li | 날짜: 2025-02-12 | URL: https://arxiv.org/abs/2502.08643 📄 PDF
Essence
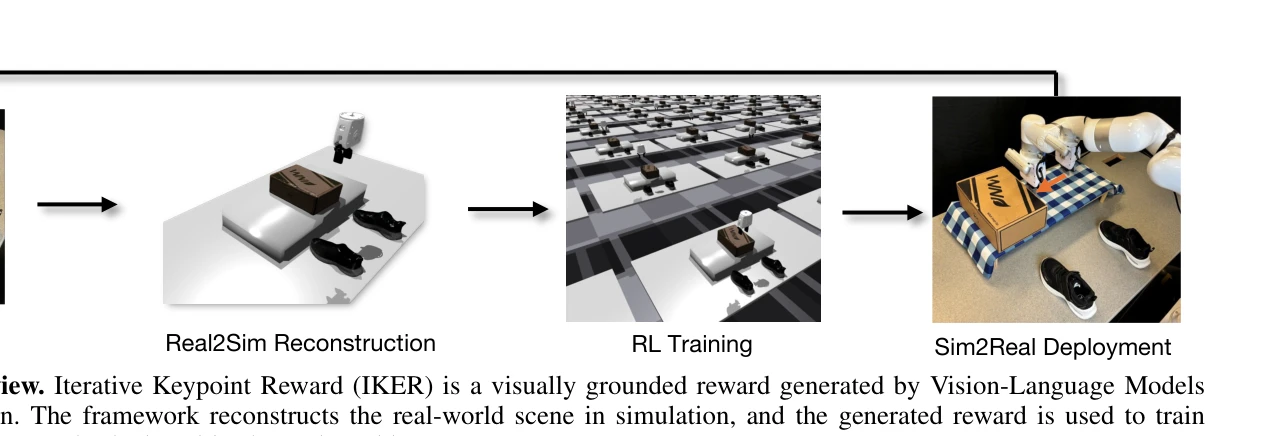
Fig. 2: Framework Overview. Iterative Keypoint Reward (IKER) is a visually grounded reward generated by Vision-Language
VLM을 활용하여 RGB-D 관찰과 자연어 지시로부터 keypoint 기반 reward 함수(IKER)를 동적으로 생성하고, real-to-sim-to-real 루프를 통해 로봇 조작 정책을 학습 및 배포하는 프레임워크이다.
Evaluation
Novelty: 4/5 Technical Soundness: 3/5 Significance: 4/5 Clarity: 4/5 Overall: 4/5
총평: 이 논문은 VLM의 시각적 이해와 RL의 최적화를 real-to-sim-to-real 루프로 통합하여 개방형 환경에서의 적응적 다단계 로봇 조작을 달성하는 창의적이고 실용적인 접근법을 제시한다. 반복적 reward 개선과 환경 피드백 기반 동적 계획이 핵심 강점이며, 다양한 실제 작업 시연을 통해 효과성을 입증했다.

